
Comprender los fundamentos de los MCP y por qué surgieron cuando contamos con LLM tan potentes.
Los LLM tienen limitaciones.
Pueden responder a tus preguntas, redactar procedimientos, proporcionar instrucciones paso a paso, comprender y generar textos, razonar y resolver problemas, y recuperar conocimientos.
Pero los LLM no pueden realizar acciones como ejecutar código, enviar correos electrónicos, llevar a cabo pasos ordenados, reservar algo o ejecutar flujos de trabajo.
A menudo pensamos que los LLM pueden hacer muchas cosas, pero en esencia son modelos de predicción avanzados que son muy buenos generando texto.
Si estás familiarizado con Cursor, Augment o GitHub Copilot, sabrás que utilizan LLM para ejecutar cambios como leer, escribir o actualizar archivos. Es interesante ver cómo estas herramientas combinan la capacidad de predicción de los LLM con la ejecución real de acciones.
La idea es que puedo crear diferentes herramientas para diferentes funcionalidades. Por ejemplo, al igual que Cursor o Copilot, puedo tener una herramienta de lectura, una herramienta de escritura, una herramienta de actualización, una herramienta de interacción con bases de datos, un ejecutor de consola o una herramienta de búsqueda en Google.
Pero también tengo que asegurarme de que estas herramientas sigan algún tipo de protocolo al crearlas.
Se puede pensar en ello como los protocolos API REST. Utilizamos las API REST de forma estandarizada para conectar el front-end y el back-end. En el caso de los LLM, actualmente no disponemos de un protocolo estandarizado para conectar las entradas y salidas.
Por ejemplo, las API utilizan códigos de estado estándar. Todo el mundo conoce y acepta en todo el mundo lo que significa cada código de estado, por lo que es fácil de adaptar y utilizar. Del mismo modo, para la conexión o la autenticación, disponemos del conjunto adecuado de protocolos que todo el mundo sigue.
Del mismo modo, al conectarnos con LLM o diseñar herramientas para LLM, también debemos tener en cuenta algún tipo de protocolo.
Con este fin, Anthropic introdujo una idea interesante llamada Model Context Protocols (MCP).
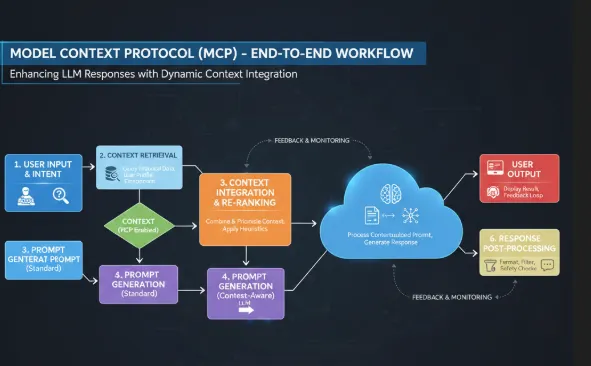
Un protocolo que define cómo los modelos de IA pueden comunicarse con contextos externos (como API, bases de datos, repositorios de código o complementos). Ayuda a los sistemas de IA a obtener la información adecuada en el momento adecuado, en lugar de depender únicamente de su preentrenamiento.
Fuentes de datos externas → por ejemplo, la base de datos de una empresa, API, documentos, registros.
Herramientas y servicios → por ejemplo, Jira, GitHub, Slack, SQL, API en la nube.
Entorno local → por ejemplo, archivos en su máquina, configuraciones, repositorios de código.
Este contexto no forma parte de los pesos de entrenamiento del modelo, sino que es algo a lo que el modelo puede acceder dinámicamente en tiempo de ejecución a través de MCP.
¿Por qué es importante el contexto?
Hay miles de repositorios, pero el LLM necesita saber qué repositorio tomar y con cuál trabajar. No queremos soluciones generalizadas, queremos soluciones relacionadas con nuestro contexto y nuestros problemas específicos.
Por lo tanto, el contexto puede ser herramientas, entornos, indicaciones o recursos.
¿Qué es un protocolo?
Un protocolo en informática es un conjunto de reglas y estándares que definen cómo se comunican dos sistemas entre sí.
Es similar a las solicitudes que hacemos para conectarnos con las API.
Arquitectura del cliente y el servidor MCP
Servidor MCP
El componente que proporciona el contexto (por ejemplo, una fuente de datos, una herramienta o un servicio). Sirve a la IA con información.
Ejemplos:
Servidor MCP de GitHub → proporciona información del repositorio.
Servidor MCP de SQL → proporciona resultados de consultas.
Servidor MCP de Jira → proporciona datos de tickets.

Cliente MCP
El componente que consume contexto (normalmente el modelo de IA o la aplicación que lo aloja). Solicita información a los servidores MCP cuando el modelo necesita conocimientos o acciones adicionales.
Ejemplos:
Claude (o GPT) actuando como cliente MCP → pregunta al servidor MCP de GitHub: «Dame las solicitudes de incorporación de cambios abiertas».
Tu aplicación basada en IA que utiliza MCP → se conecta a un servidor MCP SQL para obtener datos.
Cliente = IA que solicita contexto
Servidor = Herramienta o fuente de datos que proporciona contexto
Qué contiene un servidor MCP
Un servidor MCP es esencialmente un envoltorio alrededor de tus datos o herramientas, para que el cliente de IA pueda utilizarlos de forma segura.
Normalmente contiene:
API / Fuentes de datos → La fuente real de información (bases de datos, API, archivos, registros).
Ejemplo: API de Jira, base de datos SQL, sistema de archivos.
Herramientas (acciones) → Pequeñas funciones o comandos que el LLM puede invocar.
Ejemplo:list_issues,get_pull_requests,query_database.
Esquema / Definiciones → Una descripción estructurada de lo que el servidor puede hacer.
Reglas de seguridad → Definen lo que la IA puede hacer de forma segura.
Analogía
[He tomado esta analogía de ChatGPT para explicar las cosas mejor. Gracias, ChatGPT].
Piensa en un servidor MCP como una máquina expendedora:
En su interior hay aperitivos (API/datos).
Los botones son las herramientas (acciones).
Las etiquetas son el esquema (cómo utilizarlas).
La ranura para monedas/seguridad garantiza la seguridad.
El cliente (IA) solo tiene que pulsar los botones para obtener el aperitivo adecuado.
Ejemplo: servidor MCP de GitHub
Contiene: conexión a la API de GitHub.
Herramientas: list_repos, get_pull_requests, create_issue.
Esquema: definición JSON de las entradas necesarias.
Seguridad: permite leer repositorios, pero no eliminarlos.
Así que cuando el LLM (cliente) pregunta:
«Busca todas las PR abiertas en el repositorio XYZ».
El servidor MCP:
- Ejecuta la llamada a la API de GitHub.
- Devuelve los resultados en formato estructurado.
Servidor MCP = API + herramientas + esquema + reglas de seguridad
Cliente = aplicación de IA que solicita datos
Protocolo = las reglas sobre cómo se comunican
Gracias por leer Código en casa.




