
Todo desarrollador que trabaja con LLM en grandes bases de código termina encontrándose con el mismo obstáculo: las ventanas de contexto son finitas, pero las bases de código no lo son. El enfoque tradicional —volcar archivos sin procesar dentro del prompt y esperar lo mejor— escala de forma lineal en cuanto al consumo de tokens, pero de manera inferior a la lineal en términos de comprensión real.
Andrej Karpathy describió recientemente su flujo de trabajo personal para gestionar el conocimiento: guarda artículos académicos, capturas de pantalla y publicaciones de X en una carpeta sin procesar; después, utiliza un LLM para convertir todo ese contenido en una wiki y navegar por ella mediante Obsidian.
Terminó su descripción con un desafío:
«Creo que existe una oportunidad para crear un producto nuevo e increíble, en lugar de depender de una colección improvisada de scripts».
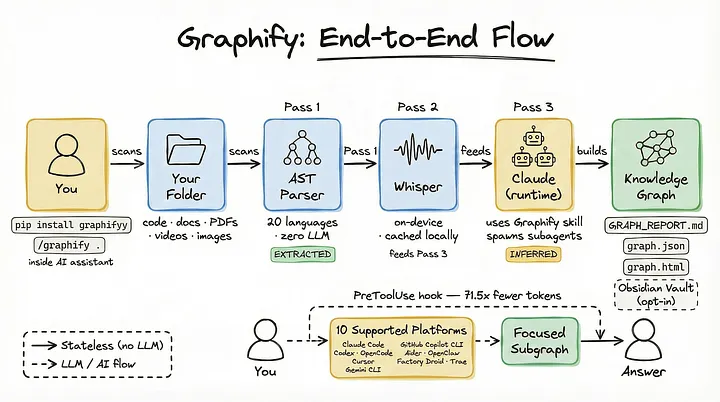
Graphify es ese producto. Adopta un enfoque fundamentalmente distinto para gestionar el contexto. En lugar de enviar archivos sin procesar a tu asistente de IA, construye un grafo de conocimiento persistente y consultable a partir de tu código, documentación, artículos, imágenes y vídeos. Después, proporciona subgrafos comprimidos a tu asistente de IA.
A continuación, encontrarás una guía paso a paso sobre cómo funciona Graphify internamente y cómo puedes utilizarlo para reducir el consumo de tokens hasta 71,5 veces.
Paso 1: instalarlo y señalar una carpeta
Comenzar a utilizar Graphify no requiere ninguna configuración. No es una capa añadida sobre una base de datos vectorial ni exige configurar complejos procesos de generación de embeddings.
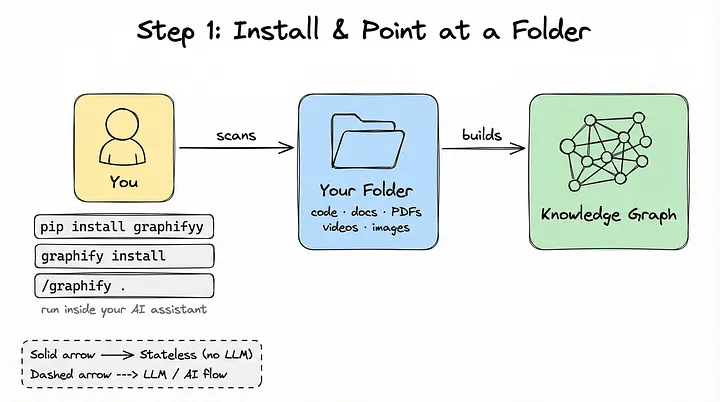
Solo tienes que instalar el paquete mediante pip y ejecutar un único comando dentro del directorio de tu proyecto:
pip install graphifyy
graphify .
Graphify comienza inmediatamente a analizar tus archivos —ya sean archivos de código, documentos PDF, imágenes o vídeos— y empieza a construir el grafo.
Paso 2: primera pasada — análisis determinista mediante AST
La primera pasada del proceso de Graphify es completamente determinista y se ejecuta localmente en tu equipo. Durante esta fase no se envía ningún fragmento de código a ninguna API de un LLM.
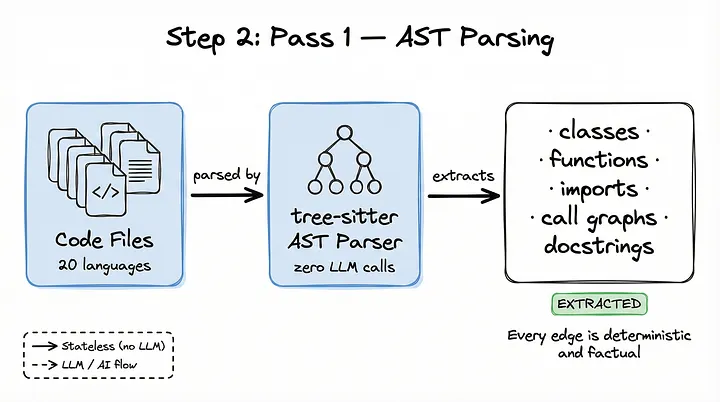
Graphify utiliza tree-sitter para analizar código escrito en 20 lenguajes diferentes. Extrae clases, funciones, importaciones, grafos de llamadas, docstrings y comentarios que explican las decisiones tomadas.
Como esta extracción es determinista, cada relación creada durante esta pasada se etiqueta con una procedencia EXTRACTED y una puntuación de confianza de 1.0. De este modo, siempre sabes que esas relaciones representan hechos verificables dentro de tu base de código.
Paso 3: segunda pasada — transcripción local
Cuando una carpeta contiene archivos de audio o vídeo —como grabaciones de clases o reuniones en formato MP4—, Graphify los procesa mediante una segunda pasada local.
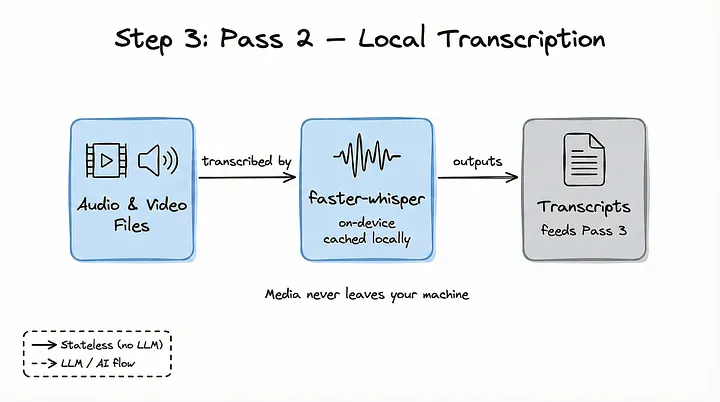
Mediante faster-whisper, Graphify transcribe estos archivos multimedia directamente en tu dispositivo. El audio nunca sale de tu equipo.
Además, las transcripciones se almacenan en caché utilizando SHA-256. Esto significa que, si vuelves a ejecutar Graphify, el proceso de transcripción será instantáneo, salvo que el archivo multimedia haya cambiado.
Estas transcripciones se envían posteriormente a la última fase de extracción.
Paso 4: tercera pasada — extracción paralela mediante LLM
En el caso del contenido semántico no estructurado —como documentación, archivos PDF, imágenes y las transcripciones generadas durante la segunda pasada— no es posible realizar un análisis determinista. Es en este punto donde Graphify aprovecha los LLM.
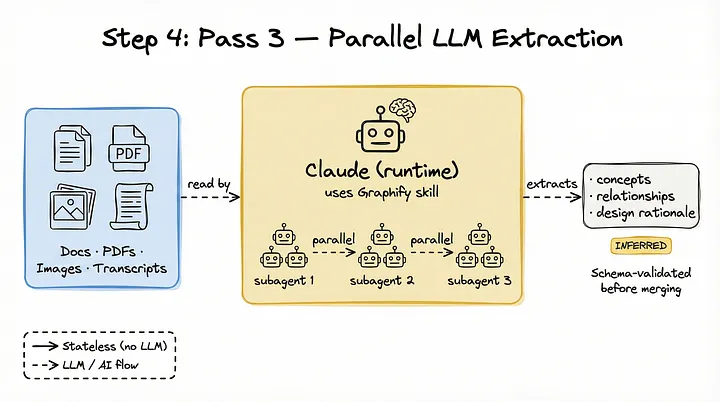
Es importante señalar que Graphify es una habilidad o skill, no un orquestador independiente. Claude u otra herramienta CLI de programación actúa como entorno de ejecución.
Esto significa que tu asistente de programación —Claude, Codex u otro similar— utiliza la habilidad de Graphify para desplegar subagentes en paralelo. Cada subagente lee el contenido y extrae conceptos, relaciones y las razones que justifican determinadas decisiones de diseño.
El resultado generado por estos subagentes se valida estrictamente mediante un esquema antes de incorporarse al grafo principal.
Como estas relaciones son deducidas por una IA, se etiquetan con una procedencia INFERRED, junto con una puntuación de confianza.
Paso 5: resultado del grafo de conocimiento
Una vez completadas las tres pasadas, Graphify genera un grafo de conocimiento estructurado y persistente.
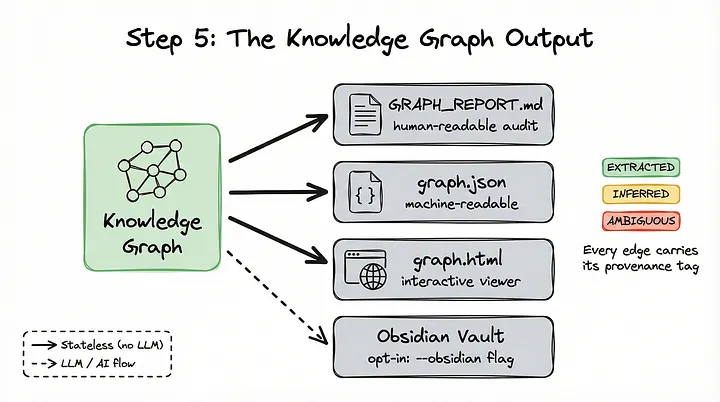
El resultado se presenta en tres formatos:
GRAPH_REPORT.md: un informe de auditoría legible para personas que resume el grafo y muestra cualquier relación que deba ser revisada manualmente.
graph.json: un archivo legible por máquinas, diseñado para que los asistentes de IA puedan consultarlo.
graph.html: un visor interactivo del grafo que permite hacer clic en los nodos, realizar búsquedas y filtrar la información por comunidades.
También puedes activar opcionalmente la generación de un Vault de Obsidian mediante el indicador --obsidian. Esto crea una wiki lista para utilizar, con enlaces bidireccionales, que permite navegar por el grafo de forma visual y textual, al igual que en el flujo de trabajo de Karpathy.
Cada relación del grafo incluye una etiqueta de procedencia: EXTRACTED, INFERRED o AMBIGUOUS. Esto garantiza la honestidad epistémica del sistema, ya que siempre puedes saber qué información encontró directamente y cuál fue inferida o considerada ambigua.
Paso 6: consultar el grafo
El verdadero potencial de Graphify se manifiesta cuando lo integras con tu asistente de programación basado en IA.
Actualmente, es compatible con diez plataformas:
Claude Code, Codex, OpenCode, Cursor, Gemini CLI, GitHub Copilot CLI, Aider, OpenClaw, Factory Droid y Trae.
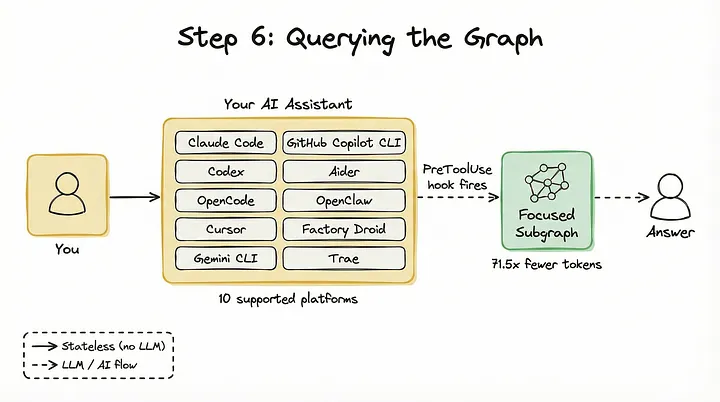
Graphify incluye un hook PreToolUse.
Cuando le haces una pregunta a tu asistente, como «¿cómo funciona el flujo de autenticación?», el hook se ejecuta antes de que el asistente comience a buscar entre los archivos sin procesar mediante herramientas como grep.
El asistente consulta primero el mapa del grafo, identifica los nodos relevantes y recupera un subgrafo específico.
En lugar de introducir 52 archivos completos dentro de la ventana de contexto, el asistente recibe un subgrafo altamente relevante de, quizá, 300 tokens.
Este contexto estructural permite que la IA proporcione respuestas precisas utilizando una cantidad de tokens drásticamente menor.
Conclusiones
Al analizarlo en conjunto, Graphify representa un avance en la forma en que los asistentes de IA consumen información. Y sí, está relacionado con el próximo gran cambio de la IA agéntica: el grafo de contexto.
El principio es sencillo: los grafos de conocimiento estructurados, comprimidos y etiquetados según su procedencia constituyen una representación de entrada mejor que los archivos sin procesar.
Al separar la extracción determinista de la inferencia probabilística y agrupar la información en función de la topología, en lugar de utilizar embeddings, Graphify garantiza que las relaciones estructurales existentes dentro de tu proyecto se conserven y puedan consultarse.
El grafo es la ventana de contexto. Todo lo demás es simplemente búsqueda.
La próxima generación de herramientas para desarrolladores no consistirá en proporcionar más contexto a los modelos, sino en proporcionarles un contexto mejor.
Las herramientas que sean capaces de distinguir entre lo que se conoce y lo que se ha inferido, y que compriman estructuras en lugar de texto sin procesar, definirán la manera en que los equipos profesionales trabajarán con IA a gran escala.
Para probarlo hoy mismo, ejecuta lo siguiente dentro de cualquier carpeta de un proyecto:
pip install graphifyy && graphify .
Comienza con una base de código que ya conozcas bien. El grafo que genere te sorprenderá.
Gracias por leer Código en Casa.
Si esto te a ayudado y te sumo algo Dale un 👏 , compártelo con tu red o dejame un comentario para saber tu opinión.





