Ha habido una batalla constante entre la IA de código abierto y la propietaria.
La guerra ha sido encarnizada, hasta el punto de que Sam Altman dijo una vez en su visita a la India que los desarrolladores pueden intentar construir IA como ChatGPT, pero que nunca tendrán éxito en este empeño.
Pero se ha demostrado que Sam estaba equivocado.
Un equipo de investigadores ha publicado recientemente un artículo de investigación en ArXiv que muestra cómo se pueden ensamblar múltiples LLM de código abierto para lograr un rendimiento de vanguardia en múltiples puntos de referencia de evaluación de LLM, superando a GPT-4 Omni, el modelo ápice de OpenAI.

Llamaron a este modelo Mezcla de Agentes (MoA).
Demostraron que una Mezcla de Agentes formada únicamente por LLM de código abierto obtuvo un 65,1% en AlpacaEval 2.0, frente al 57,5% de GPT-4 Omni.
Esto es impresionante.
Esto significa que el futuro de la IA ya no está en manos de las grandes tecnológicas que construyen software a puerta cerrada, sino que es más democrático, transparente y colaborativo.
También significa que los desarrolladores ya no pueden centrarse en entrenar un solo modelo en varios billones de fichas, lo que requiere un requisito informático increíblemente costoso de cientos de millones de dólares.
En su lugar, pueden aprovechar la experiencia colaborativa de múltiples LLM con diversos puntos fuertes para obtener resultados impresionantes.
En este artículo profundizamos en el modelo de mezcla de agentes, en qué se diferencia de la mezcla de expertos (MoE) y cómo funciona en distintas configuraciones.
¿Cómo funciona la mezcla de agentes?
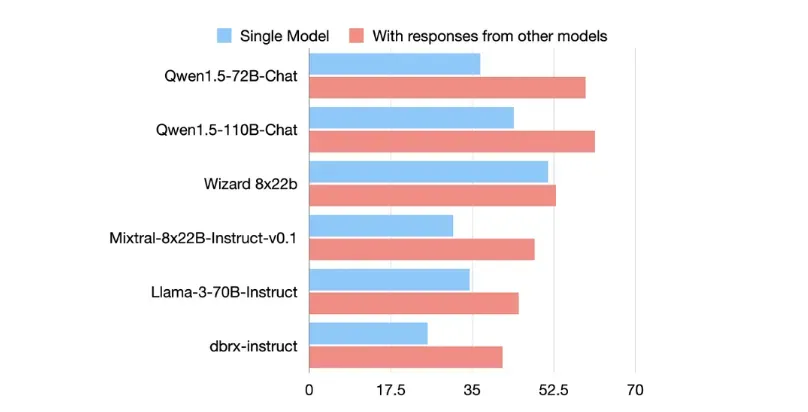
El modelo de Mezcla de Agentes (MoA) se basa en un fenómeno denominado « Colaboración de los LLM».
Es cuando un LLM genera mejores respuestas cuando se le dan los resultados de otros LLMs, incluso cuando estos otros LLMs son menos capaces por sí mismos.
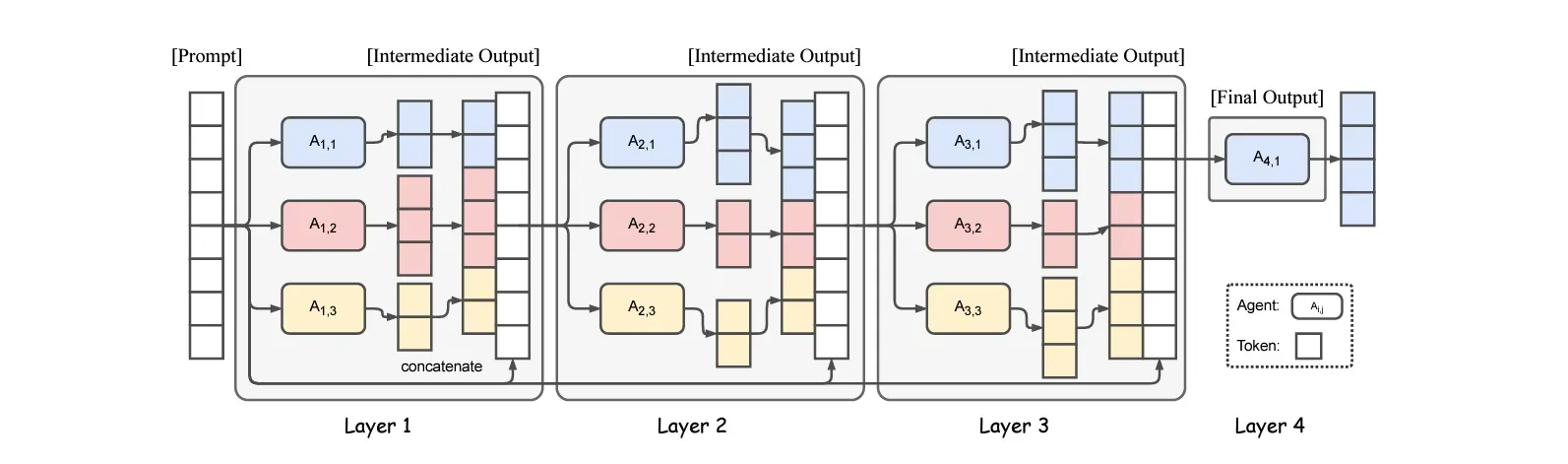
Aprovechando este fenómeno, el modelo MoA se organiza en múltiples capas, cada una formada por múltiples LLM (agentes).
Cada agente LLM de una capa recibe información de todos los agentes de la capa anterior y genera una salida basada en la información combinada.
Así es como funciona en detalle.
Los agentes LLM de la primera capa reciben una pregunta.
Las respuestas que generan se transmiten a los agentes de la capa siguiente.
Este proceso se repite en cada capa, donde cada capa refina las respuestas generadas por la anterior.
La última capa agrega las respuestas de todos los agentes y da lugar a un único resultado de alta calidad del modelo global.
Consideremos un modelo MoA formado por l capas, en el que cada capa i contiene n LLM (cada una de ellas denominada A(i,n)).
Para una entrada dada x(1), la salida de la capa i-ésima, denominada y(i), puede expresarse de la siguiente manera.
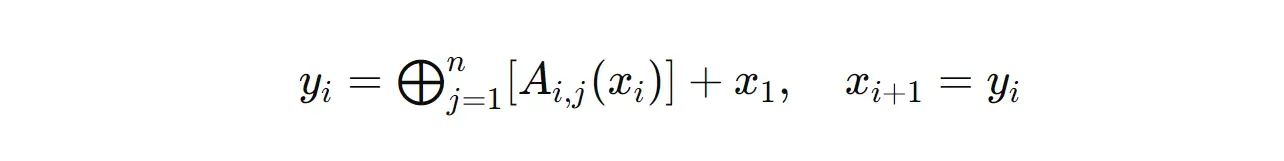
donde:
y(i)es la salida de la capai-ésimaA(i,j)es elj-ésimoagente LLM de la capai-ésimax(i)es la entrada de la capai-ésima+representa la concatenación de textos⨁representa la aplicación de la orden de agregar y sintetizar a las salidas (se muestra en la imagen siguiente)

Sólo se utiliza un agente LLM (A(1,l)) en la última capa (l) y esta salida es la respuesta final del modelo MoA utilizada para la evaluación del modelo.
Funciones de los distintos agentes LLM en la mezcla de agentes
Los LLM utilizados en una capa de MoA pueden ser de dos tipos diferentes:
- Proponentes: El papel de estos LLMs es generar diversas respuestas que pueden no puntuar muy alto en las métricas de rendimiento individualmente.
- Agregadores: El papel de estos LLM es agrupar las respuestas procedentes de los Proponentes para generar una única respuesta de alta calidad.
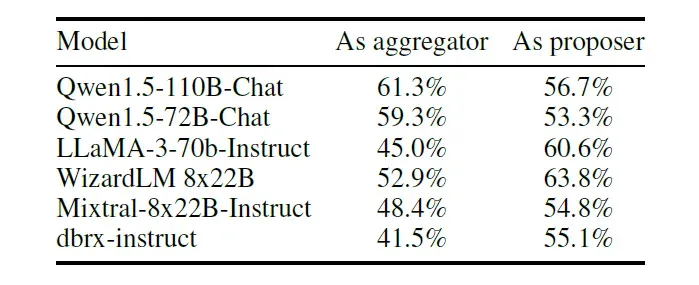
Se observó que Qwen1.5 y LLaMA-3 eran eficaces tanto como Proponentes como Agregadores.
Por otro lado, WizardLM y Mixtral-8x22B fueron mejores cuando se utilizaron como Proponentes.
Espera, pero esto se parece un poco al modelo de mezcla de expertos
Sí. El modelo MoA se inspira en el modelo de mezcla de expertos (MoE). Pero también hay diferencias considerables.
Aprendamos primero qué es el modelo de mezcla de expertos.
Propuesto en 2017, el modelo MoE combina múltiples redes neuronales llamadas Expertos que se especializan en diferentes conjuntos de habilidades (comprensión del lenguaje natural, generación de código, resolución de problemas matemáticos y más).
Un modelo MoE consta de múltiples capas denominadas capas MoE que, a su vez, contienen múltiples redes de expertos.
Estos expertos se activan de forma selectiva en función de la entrada dada, y una red Gating se encarga de esta tarea.
Esta red asigna diferentes pesos a las salidas de los distintos expertos, controlando así su influencia en la salida combinada por la red Gating.
Para una capa MoE, su salida puede expresarse matemáticamente de la siguiente manera.
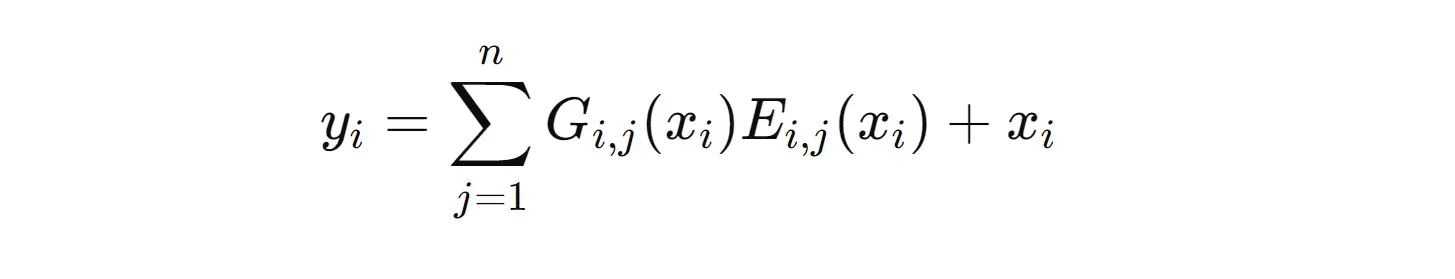
Donde:
x(i)es la entrada a lai-ésimacapa MoEG(i,j)es la salida de la red de compuerta correspondiente alj-ésimoexperto en lai-ésimacapaE(i,j)es la función calculada por elj-ésimoexperto en lai-ésimacapa.
Aunque parecen muy similares, cuando se comparan con MoE, el modelo MoA
- utiliza LLM completos en lugar de subredes en las distintas capas
- agrega los resultados de varios agentes mediante un indicador (Aggregate-and-Synthesize prompt) en lugar de una red Gating
- elimina la necesidad de ajuste fino y modificación interna de la arquitectura LLM y puede utilizar cualquier LLM por sí solo como parte
Rendimiento del modelo de mezcla de agentes
El modelo MoA construido por los investigadores estaba formado por los siguientes modelos:
- Qwen1.5-110B-Chat
- Qwen1.5-72B-Chat
- WizardLM-8x22B
- LLaMA-3-70B-Instrucción
- Mixtral-8x22B-v0.1
- dbrx-instruct
La estructura del modelo incluía tres capas con el mismo conjunto de modelos en cada capa.
Qwen1.5-110B-Chat se utilizó como agregador en la última capa.
Junto a ésta se crearon otras dos variantes, a saber
- MoA con GPT-4o: Esta variante utilizó GPT-4o como agregador en la capa final.
- MoA-Lite: Esta variante utilizaba dos capas en lugar de tres, con Qwen1.5-72B-Chat como agregador en la capa final. Su objetivo era reducir el coste global asociado al uso del modelo.
El rendimiento de estas arquitecturas se evaluó utilizando tres puntos de referencia estándar -
Los resultados se muestran a continuación.
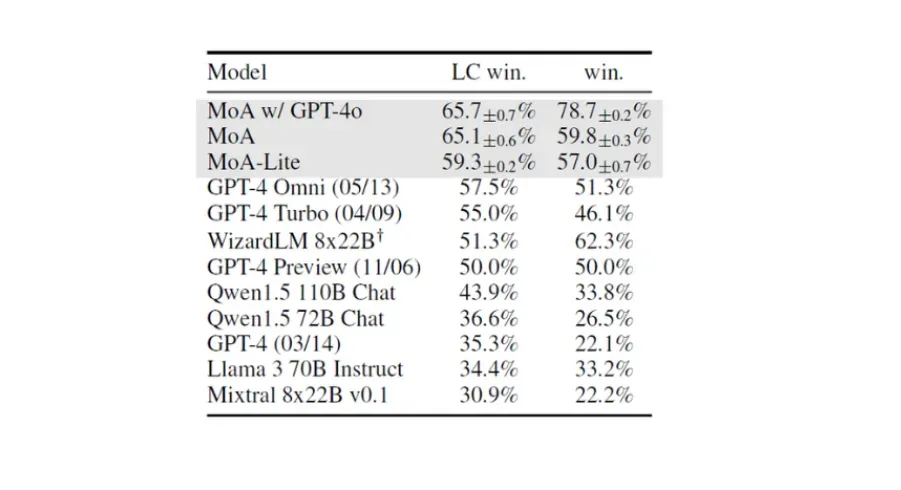
Rendimiento en AlpacaEval 2.0
Durante la evaluación, la métrica 'Win' mide la tasa de preferencia de la respuesta de un modelo comparada con la del GPT-4 (gpt-4-1106-preview), con un evaluador basado en el GPT-4.
Otra métrica -'Length-controlled (LC) Win', garantiza una comparación más justa ajustando la longitud de respuesta de cada modelo para neutralizar el sesgo de longitud.
El modelo MoA logró una impresionante mejora absoluta del 8,2% en LC Win con respecto al GPT-4o. Incluso la variante económica MoA-Lite superó a GPT-4o en un 1,8% en esta métrica.
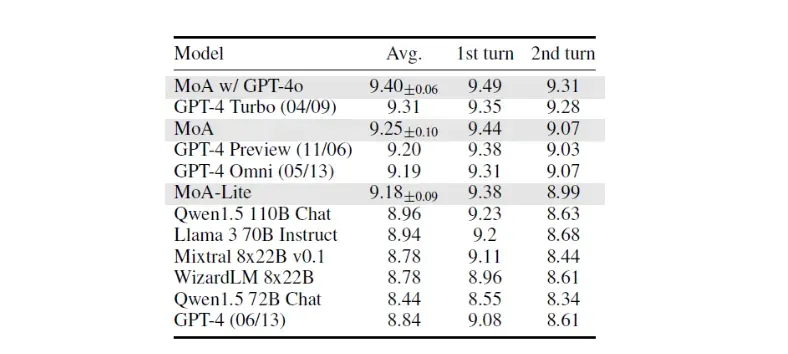
Rendimiento en MT-Bench
Este benchmark utiliza tres métricas que puntúan los modelos sobre 10.
- Avg: la puntuación media global obtenida por un modelo
- 1er turno: puntuación de la respuesta inicial
- 2º turno: puntuación de la respuesta de seguimiento en una conversación.
MoA y MoA-Lite mostraron un rendimiento muy competitivo en comparación con GPT-4o en esta prueba.
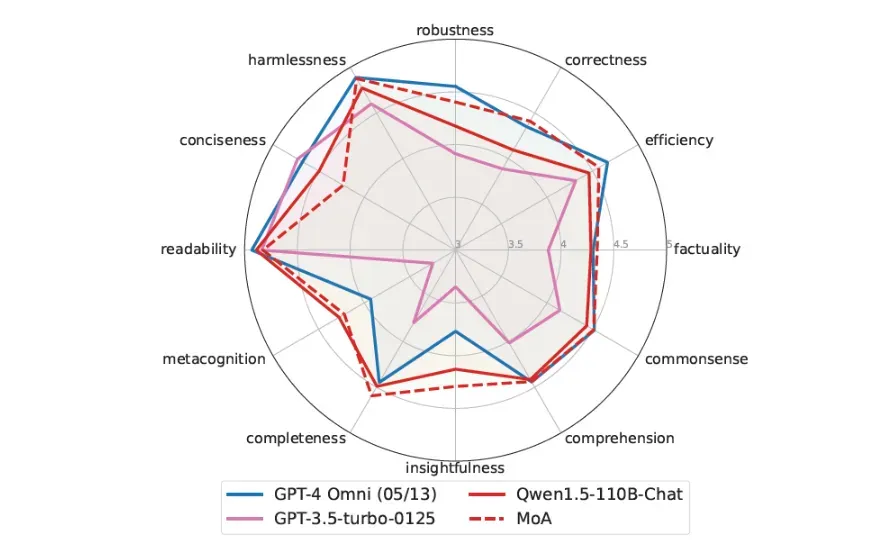
Rendimiento en FLASK
Esta prueba proporciona una evaluación más detallada del rendimiento de los modelos.
MoA sobresalió en muchas métricas de FLASK en comparación con GPT-4o, excepto en Concisión, ya que sus resultados eran más verbosos.
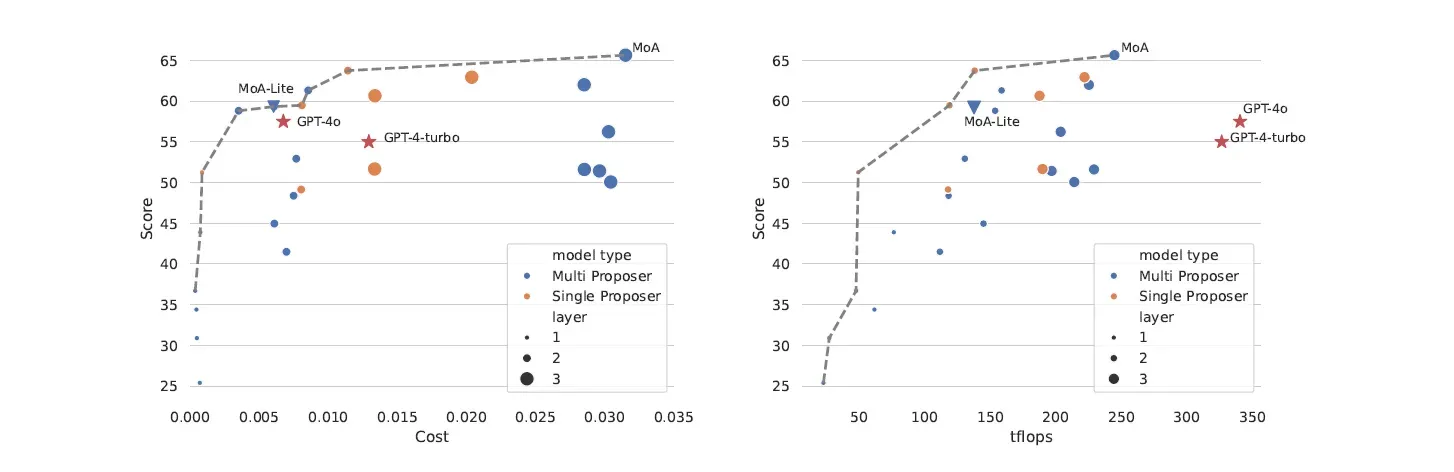
Coste y eficiencia computacional
En cuanto a la eficiencia de costes, MoA-Lite igualó el coste de GPT-4o al tiempo que conseguía una alta calidad de respuesta (mayor porcentaje de victorias en la LC).
Por lo demás, MoA fue la mejor configuración para lograr el mayor porcentaje de LC ganadas, independientemente del coste.
Este resultado fue contrario al de GPT-4 Turbo y GPT-4o, que no eran óptimos en cuanto a coste, pero sí más caros que los enfoques MoA con el mismo porcentaje de LC ganadas.
También se descubrió que MoA y MoA-Lite utilizaban sus recursos computacionales de forma más eficaz para lograr altos porcentajes de LC ganadas en comparación con GPT-4 Turbo y GPT-4o.