
El pensamiento adaptativo está activado. Los presupuestos manuales desaparecieron. La facturación cambió por completo.
Hace poco vimos una lista con 6 consejos sobre cómo mejorar el uso de la herramienta, pero se omitió por completo una conversación vital: los cambios que rompieron flujos de trabajo enteros y que llegaron de la mano con esta nueva versión.
Esto es lo que no nos contaron.
3 cambios que rompen tu flujo de trabajo
Anthropic acaba de lanzar Opus 4.7. También publicaron una guía de migración, esa que la mayoría de las personas probablemente no va a leer.
Sin embargo, hay 3 cambios críticos que necesitamos conocer ahora mismo:
budget_tokensahora devuelve un error 400.- El nuevo tokenizador está cobrando un 35% más de tokens.
- Los tokens de pensamiento están ocultos por defecto.
Veamos en detalle cada uno de ellos.
1. budget_tokens está roto
Si tu código tiene esta configuración:
JSON
thinking={"type": "enabled", "budget_tokens": 32000}
En Opus 4.7 eso ahora devuelve un error 400. No hubo aviso previo de obsolescencia; simplemente comenzó a fallar.
Esto representa un verdadero dolor de cabeza cuando se trabaja con Opus a gran escala. Los presupuestos de pensamiento, que utilizábamos para mantener el control de los costes, desaparecieron por completo.
Este es el reemplazo que debes implementar:
JSON
thinking={"type": "adaptive"}
output_config={"effort": "xhigh"}
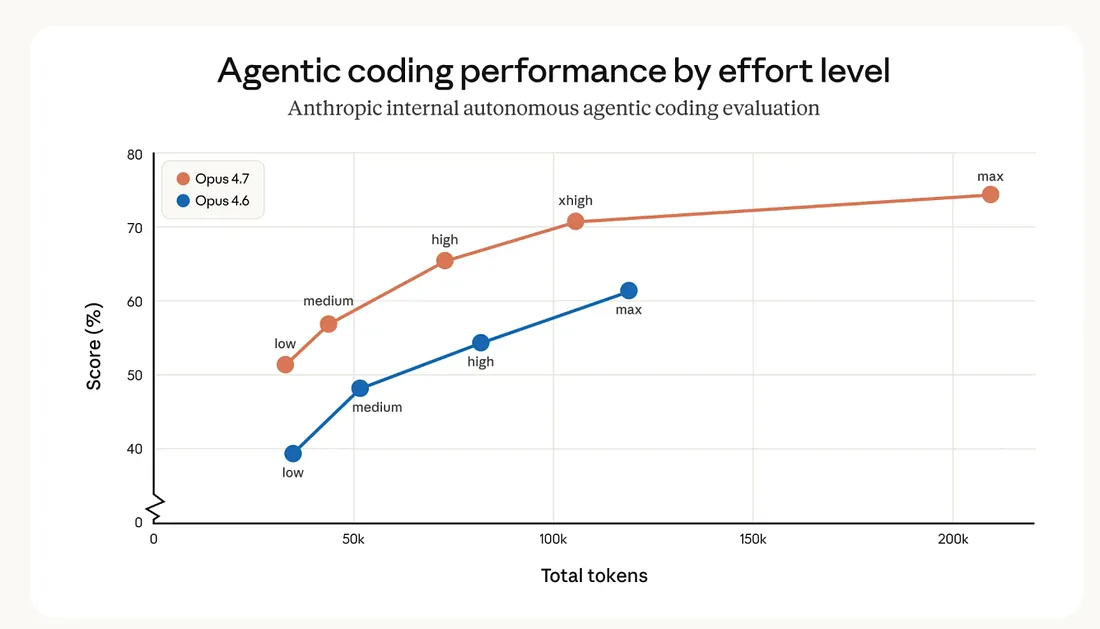
Los niveles de esfuerzo disponibles ahora son: low, medium, high, xhigh —nuevo—, y max.
Debes tener en cuenta que el pensamiento adaptativo está desactivado por defecto en Opus 4.7. Esto significa que el modelo se ejecutará sin procesar pensamientos previos. Te sugiero tener muchísimo cuidado al actualizar el nombre del modelo de 4.6 a 4.7; la configuración por defecto ahora es bastante más deficiente.
2. El tokenizador ahora usa más tokens
Todo esto ocurre al mismo precio por token y con la misma ventana de contexto de 1 millón —no, lamento decir que eso no aumentó—.
Sin embargo, el nuevo tokenizador consume 1,35 veces más tokens para el mismo texto. Además, muchos reportes sugieren que el modelo se ve más afectado por la degradación del contexto.
Así que, en la práctica, nos encontramos con que el precio subió, pero la experiencia desde nuestro lado no ha mejorado demasiado. No nos dejemos engañar por los benchmarks internos del tipo “confía en mí, bro”.
Otras tres cosas enormes que ahora debemos considerar son:
- Cualquier presupuesto de contexto que hayas dejado codificado de forma fija ahora es erróneo.
- Cualquier estimación de tokens del lado del cliente ahora es incorrecta.
- Tu factura de la API será más alta por el mismo prompt de siempre.
3. Los tokens de pensamiento siguen ocultos
Este punto sigue siendo especialmente incómodo. De hecho, escribí una publicación reciente sobre esto.
En Opus 4.6, hasta hace poco, el contenido de pensamiento se mostraba por defecto como “resumido”. En Opus 4.7, ahora aparece por defecto como “omitido”. Los bloques de pensamiento se muestran vacíos en la respuesta, pero aun así los pagas por completo.
“Se te sigue cobrando por todos los tokens de pensamiento. Omitirlos reduce la latencia, no el coste.”
Eso viene directamente de las especificaciones de Anthropic. El resultado es que tu factura incluirá tokens que ya ni siquiera puedes ver.
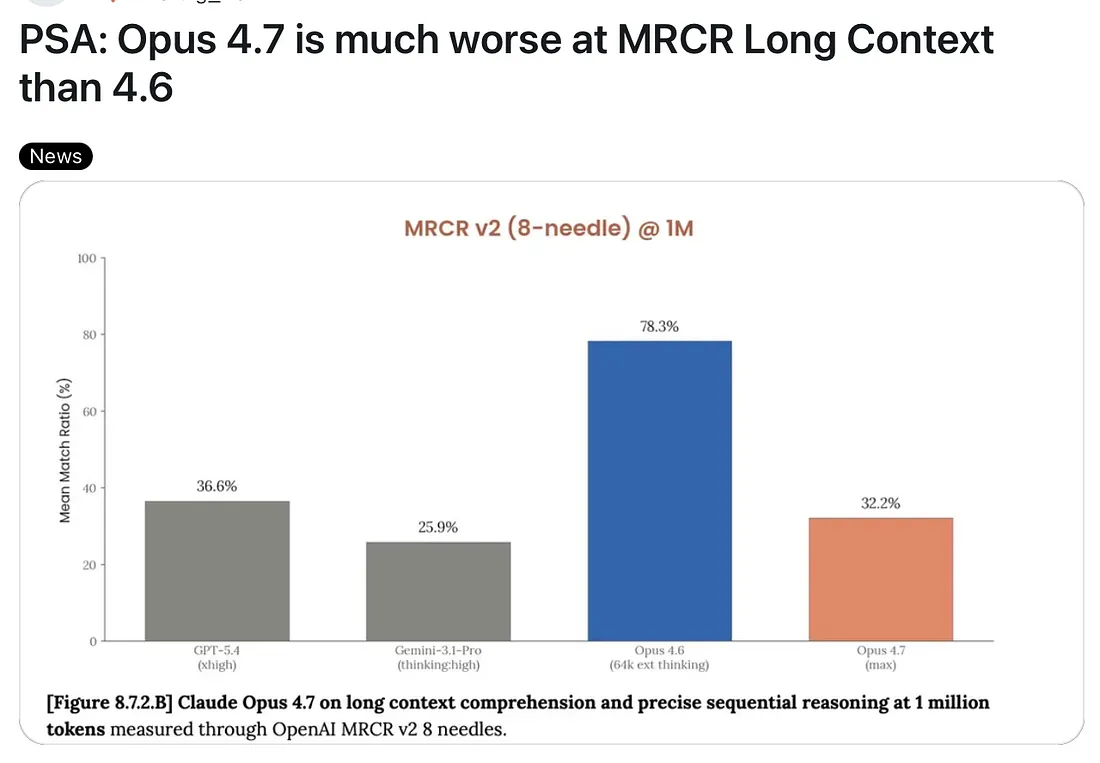
La recuperación en contexto largo acaba de caer por un precipicio
En los benchmarks MRCR v2 con 1 millón de tokens, los resultados hablan por sí solos:
- Opus 4.6: 78,3%
- Opus 4.7: 32,2%
Estamos hablando de una regresión de 46 puntos en un benchmark que la propia Anthropic publicó.
Lo que los desarrolladores están reportando realmente
La respuesta general de la comunidad ha sido bastante dura. Incluso Opus 4.7 está confesando abiertamente que inventa información.
Otros patrones que están apareciendo en el uso real:
Alucina compañeros de trabajo y personas aleatorias.
Démoslo por terminado por hoy.
Preferencias configuradas que están siendo completamente ignoradas.
Anthropic aumentó los límites de uso, aparentemente
Tras la ola de reacciones negativas, Anthropic anunció un “aumento permanente de los límites de uso”.
Sin embargo, me mantengo muy escéptica con esto, ya que todavía no han compartido números ni porcentajes concretos. Pero supongamos que aumentan los límites entre 1,0 y 1,35 veces; bueno, eso simplemente equilibraría el nuevo consumo de pensamiento. Así que... ¿disfrútalo? Creo que no hay mucho que celebrar.
Lo que dijo Boris —y lo que no dijo—
A pesar de todo, vale la pena leer el hilo de Boris para entender su perspectiva:
- Modo automático para ejecuciones largas sin supervisión.
- Skill
/fewer-permission-promptspara reducir los bucles de aprobación. - Resúmenes para volver a sesiones largas.
- Modo enfoque para ocultar el trabajo intermedio.
- Ajuste de esfuerzo —recomienda empezar en
xhighpara programación—. - Darle a Claude una forma de verificar su propio trabajo.
Sin embargo, no esperes actualizar el modelo y que el flujo de trabajo de Boris funcione por arte de magia.
Empieza haciendo esto
Si tienes 5 minutos: busca budget_tokens en tu base de código. Configura el esfuerzo en xhigh para tareas de programación. Si usas Claude Code, configúralo también en el nivel más alto.
Si tienes 15 minutos: lee con calma las notas de lanzamiento de Anthropic y la guía de migración.
NOTA
Me encanta usar Claude Code y Claude en mi día a día. Sin embargo, estos movimientos recientes realmente me están poniendo nerviosa, y sé que no soy la única. Casi todas las personas con las que he hablado últimamente han notado una caída notable en el rendimiento, justo en el mismo momento en que nos piden que nos subamos al tren del hype.
No estoy afiliada a Anthropic ni a Claude. Todas las opiniones expresadas aquí son completamente mías.
Gracias por leer Código en Casa.
Si esto te a ayudado y te sumo algo Dale un 👏 , compártelo con tu red o dejame un comentario para saber tu opinión.





