
¿Te molesta a veces tener que esperar a que Cursor o VS Code terminen tu código, solo para que resulte ser incorrecto?
¿Qué es?
Para explicarlo mejor, supongamos que quiero hacer un seguimiento de la hora a la que escribí un artículo, cuánto tiempo tardé en escribirlo y cuántas palabras tenía.
En realidad, eso puede ser una consulta complicada que implica varios pasos. Cuantos más pasos introduzcamos, más posibilidades hay de que algo salga mal.
Así que hacemos lo anterior y obtenemos algo como esto
Introduzco los detalles de mis sesiones de escritura y debajo obtengo un campo JSON.
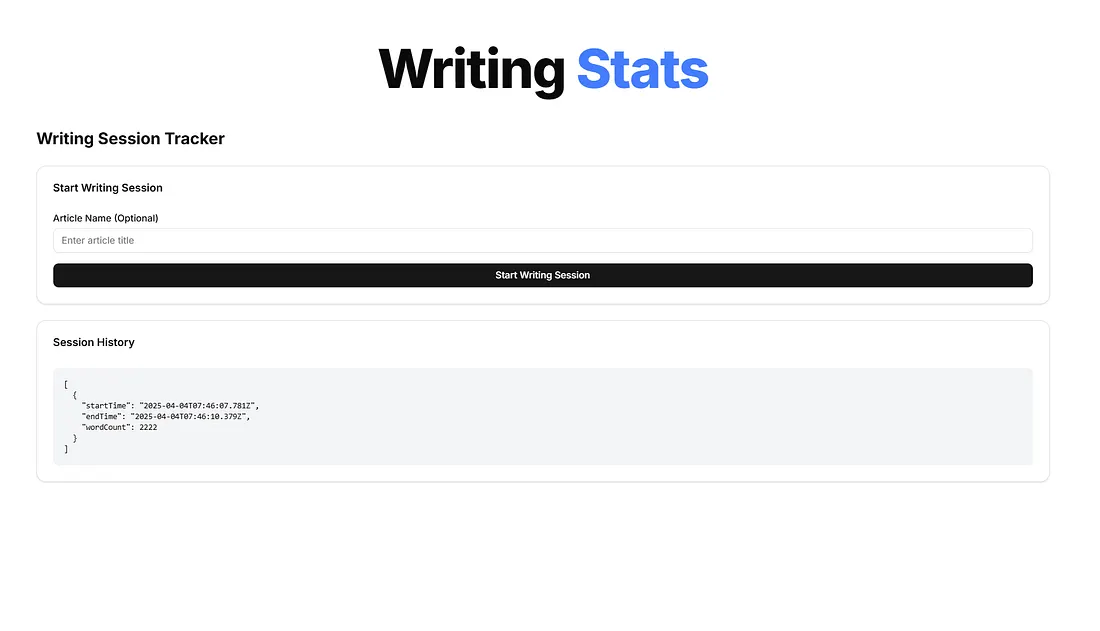
Mi salida JSON se muestra a continuación en la página. En la primera representación es incorrecta, la hora es errónea.
Aquí es bastante pequeña, pero el JSON es realmente incorrecto.
Lo hice a las 8:46 y mostraba la hora de inicio a las 7:46.
Aquí mismo se muestra lo que quiero decir con desarrollo JSON primero
- En lugar de renderizar nada en un backend, introduce un registro de impresión en la pantalla con el JSON.
- Comprueba que el JSON tiene la estructura correcta que deseas.
- Haz los cambios necesarios hasta que sea así.
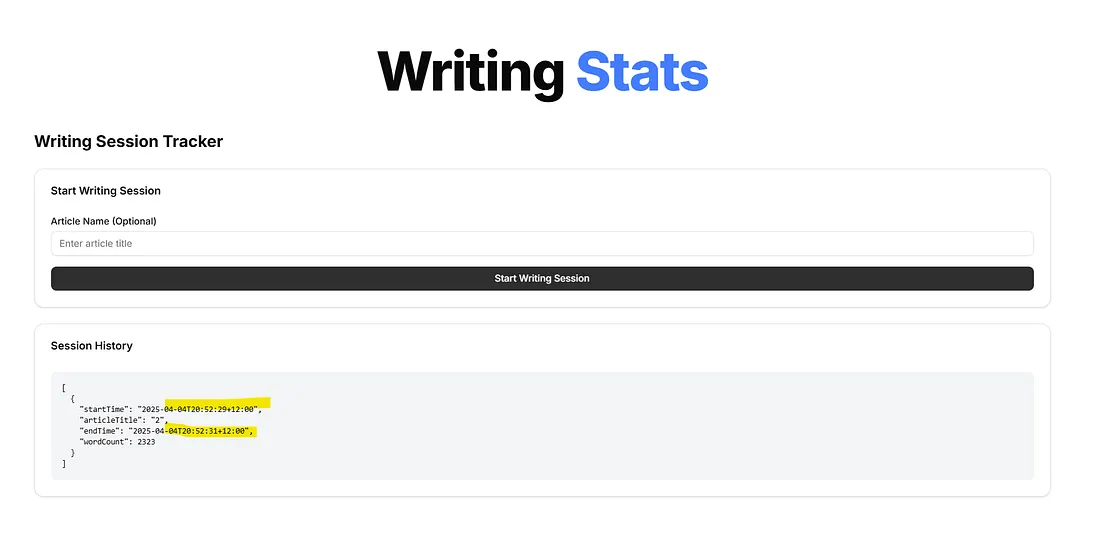
Ahora, la codificación JSON primero es mucho mejor. Simplemente le pido que actualice la página en Cursor y luego puedo volver a probar el JSON para ver el resultado.
Eso fue solo rápido y, lo que es más importante, solo había que actualizar un archivo.
Ahora, cuanto más utilizo estas herramientas, más me doy cuenta de que quiero reducir la carga tanto como sea posible. Aunque pueden hacer cosas ridículas de un solo golpe, solo dificultan la localización de errores si algo sale mal.
Ahora, cuanto más utilizo estas herramientas, más me doy cuenta de que quiero reducir la carga tanto como sea posible. Aunque pueden hacer cosas ridículas de un solo golpe, solo dificultan la localización de errores si algo sale mal.
¿Por qué es tan importante?
Esto tiene varias ventajas.
- Reduce el número de elementos con los que interactúa la IA. No hay que actualizar ningún esquema ni API.
- También permite ver el resultado, en lugar de un misterioso error en la base de datos backend que no podemos ver.
- Nos permite verificar el flujo.
Ilustremos por qué es importante con un diagrama.
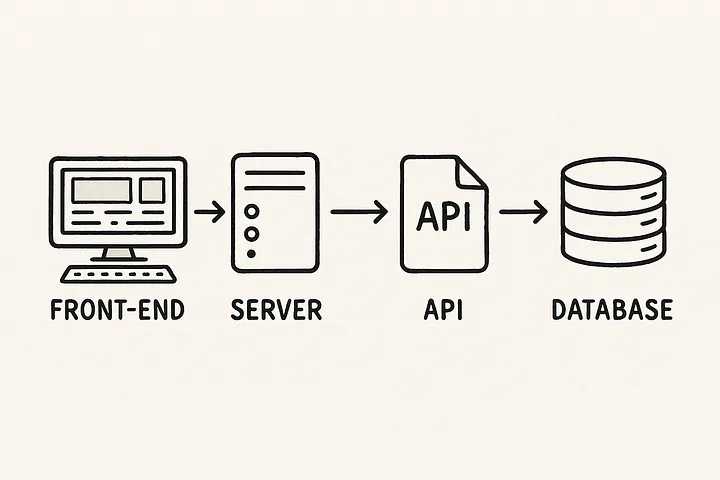
La razón por la que es bueno es porque cuando miramos una pila de llamadas normal, podemos ver que hay una serie de lugares en los que tienen que suceder cosas.

Al reducir el archivo para producir solo JSON en la interfaz, tenemos menos posibilidades de cometer errores y obtenemos más comentarios más rápidamente.
Creo que los resultados significativos y el tiempo son activos fundamentales en la codificación actual y que es importante interactuar de forma significativa con la IA en los puntos críticos tan a menudo como sea posible.
Esto siempre tiene una ventaja significativa
Si podemos ver y confirmar que nuestro JSON es correcto, ¡entonces es muy fácil hacer una API y una base de datos! A menudo, con una sola vez bastará para ambas cosas.
Este era un ejemplo sencillo, pero ¿qué pasa con los más complicados?
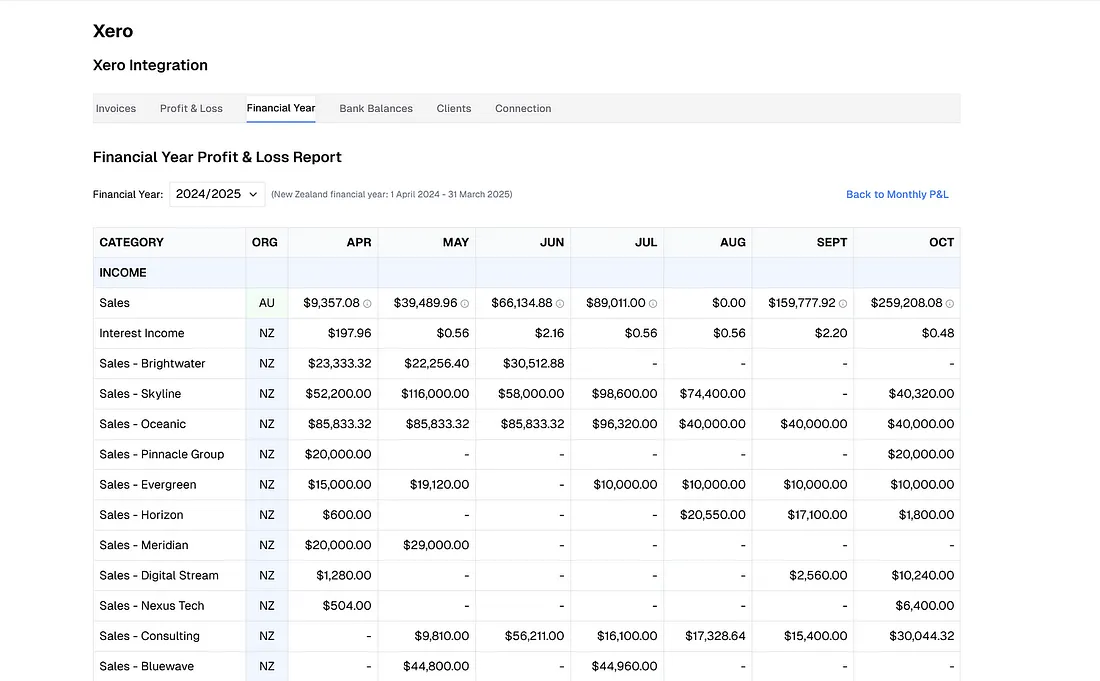
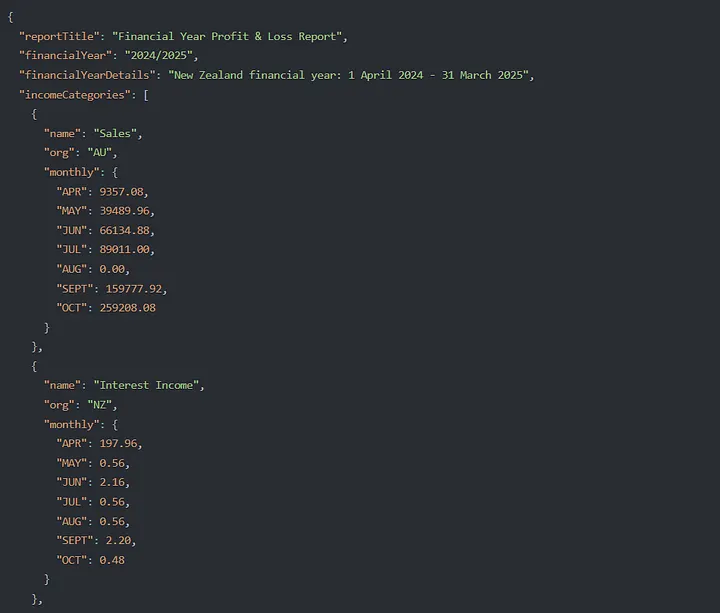
Lo anterior es un ejemplo real de un informe de pérdidas y ganancias financieras. Fíjese en todas las líneas de datos, hay muchos aspectos que pueden salir mal.
Al comenzar primero con un registro JSON, podemos comprobar si todo está como necesitamos. A continuación, construimos poco a poco la lógica con componentes front-end para asegurarnos de que manipulamos el JSON hasta que esté listo para pasar a la base de datos.
Valora tu tiempo
Después de usar estos LLM durante 10 horas al día durante el último mes, he descubierto que lo mejor es iterar lo más rápido posible.
Este estilo de desarrollo lleva un poco de tiempo acostumbrarse, ya que es un flujo de trabajo diferente al que probablemente hayas utilizado antes, pero reduce drásticamente la tasa de errores.
¿Y si solo estás trabajando en una API?
- Entonces solo tienes que renderizar un archivo JSON, se aplica el mismo principio. Solo tienes que limitar el número de cosas que necesitas que llame el LLM.
Gracias por leer Código en Casa.





