
Qué es un token OpenAI
En el ámbito de los modelos lingüísticos avanzados de OpenAI, como GPT-3.5 y GPT-4, el término "token" se refiere a una secuencia de caracteres que suelen aparecer juntos en un texto. Estos modelos están diseñados para comprender y predecir las relaciones estadísticas entre estos tokens.
El proceso de descomposición del texto en tokens puede variar entre los distintos modelos. Por ejemplo, GPT-3.5 y GPT-4 utilizan un proceso de tokenización diferente al de sus predecesores, lo que da como resultado diferentes tokens para el mismo texto de entrada.
Como norma general, un token equivale aproximadamente a cuatro caracteres en un texto en inglés, lo que equivale aproximadamente a tres cuartas partes de una palabra. Por tanto, 100 tokens equivaldrían aproximadamente a 75 palabras.
Por ejemplo, consideremos la frase "OpenAI is great!". En esta frase, los tokens podrían desglosarse de la siguiente manera:
[“Open”, “AI”, “ is”, “ great”, “!”]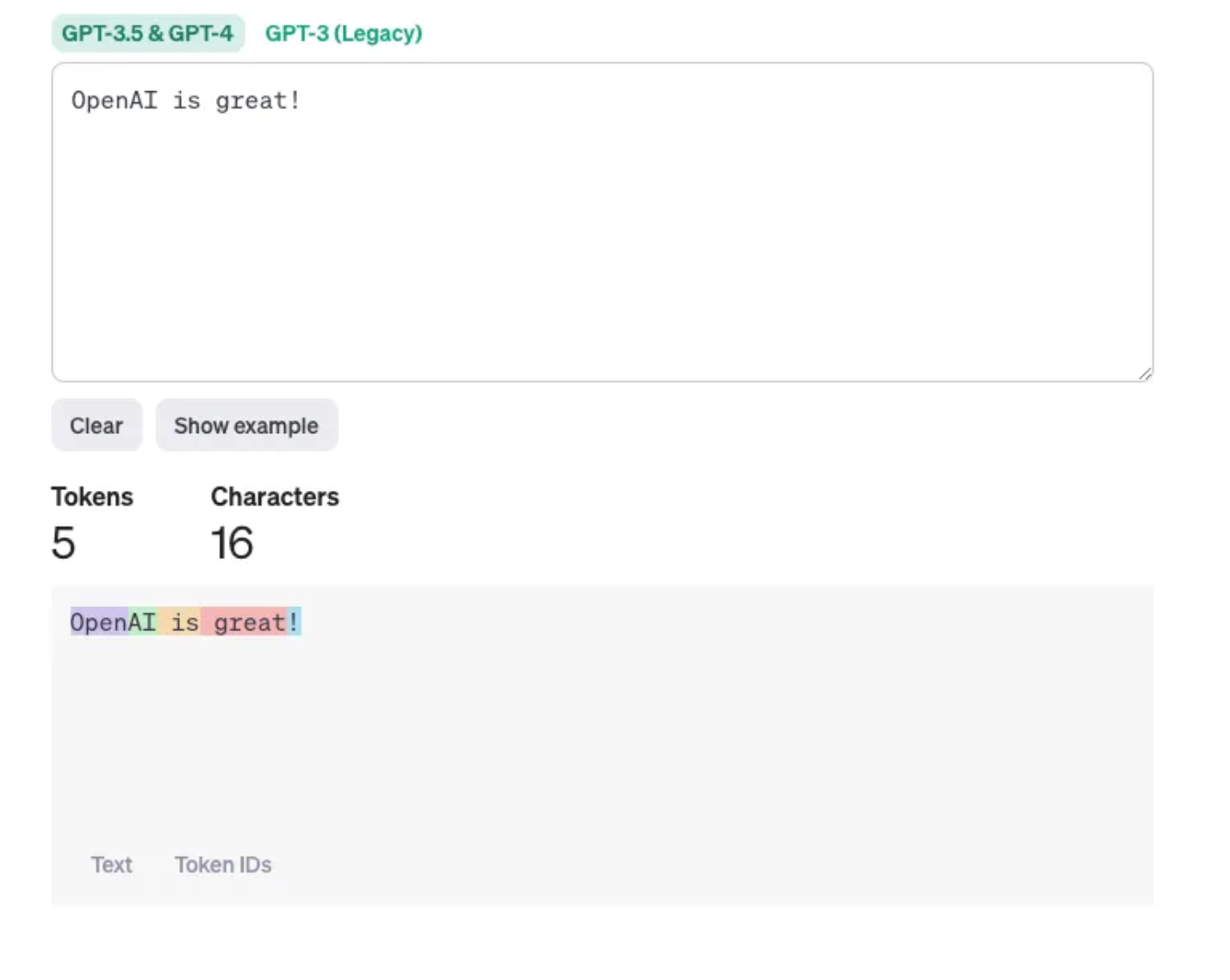
Cada uno de ellos se considera un token. El desglose exacto puede variar en función del proceso específico de tokenización utilizado por el modelo. Por ejemplo, algunos modelos pueden tratar "OpenAI" como un único token, mientras que otros pueden dividirlo en "Open" y "AI".
Del mismo modo, los espacios y los signos de puntuación suelen tratarse como fichas separadas. En este ejemplo, tenemos cinco símbolos: "Abierto", "IA", "es", "genial" y "¡!".
He aquí algunas pautas útiles para comprender el concepto de longitud de los tokens:
- 1 token equivale aproximadamente a 4 caracteres en inglés.
- 1 token equivale aproximadamente a 3/4 de una palabra.
- 100 tokens equivalen aproximadamente a 75 palabras.
Alternativamente,
- 1 ó 2 frases equivalen aproximadamente a 30 fichas.
- Un párrafo equivale aproximadamente a 100 tokens.
- Unas 1.500 palabras corresponden a 2.048 tokens.
Codificación de token
La codificación de tokens es un paso clave en el Procesamiento del Lenguaje Natural (PLN) y el aprendizaje automático. Es el proceso de convertir texto en bruto en un formato que las máquinas puedan entender y con el que puedan trabajar, normalmente vectores numéricos de dimensiones fijas.
Las distintas codificaciones de tokens están vinculadas a distintos modelos, por lo que hay que tenerlo en cuenta al convertir el texto en tokens, para saber qué modelo se va a utilizar.
Dada una cadena de texto (por ejemplo, "¡OpenAI es genial!") y una codificación (por ejemplo, "cl100k_base"), un tokenizador puede dividir la cadena de texto en una lista de tokens (por ejemplo, ["Open", "AI", " is", " great", "!"]).
La siguiente tabla muestra la correspondencia entre el método de codificación de tokens y los modelos de OpanAI:

Tokenización
En el contexto de OpenAI, la tokenización es el método de dividir el texto en fragmentos más pequeños, conocidos como tokens. Estos tokens, que suelen ser secuencias de caracteres que aparecen juntos con frecuencia en un texto, son utilizados por los grandes modelos lingüísticos de OpenAI, como GPT-3.5 y GPT-4, para procesar y comprender el texto.
Tiktoken es un herramienta basada en Python creada por OpenAI. Es esencialmente un tokenizador rápido de codificación de pares de bytes (BPE) que está diseñado para trabajar con los modelos de OpenAI como GPT-4. La función principal de Tiktoken es dividir el texto en trozos más pequeños, conocidos como tokens, que luego son utilizados por los modelos para procesar y comprender el texto.
Al ser una herramienta de código abierto, Tiktoken se puede instalar fácilmente desde PyPI utilizando el comando pip install tiktoken. También existen versiones soportadas por la comunidad para entornos JavaScript.
Una de las principales características de Tiktoken es su submódulo educativo, que proporciona información sobre el funcionamiento de BPE y permite a los usuarios visualizar el proceso de tokenización. Además, Tiktoken es flexible y permite a los usuarios añadir soporte para nuevas codificaciones.
Un ejemplo sería
import tiktoken
encoding = tiktoken.get_encoding("cl100k_base")
# To automatically load the correct encoding for a given model name
encoding = tiktoken.encoding_for_model("gpt-3.5-turbo")
print(encoding.encode("OpenAI is great!"))El resultado será el siguiente:
[5109, 15836, 374, 2294, 0]Puedes contar los tokens contando la longitud de la lista devuelta por .encode().
Límites de tokens
El número máximo de tokens disponibles para su uso en una petición varía según el modelo elegido, con un tope combinado de 4096 tokens tanto para la petición de entrada como para la salida generada (gpt-3.5-turbo).
Por lo tanto, si asigna 4000 tokens a la entrada, le quedarán un máximo de 96 tokens para la salida.
Esta limitación se debe principalmente a razones técnicas. Sin embargo, existen numerosas estrategias para trabajar eficazmente dentro de estos límites, como resumir la entrada de forma más sucinta o dividir el contenido en segmentos más manejables.
Límites de tokens para GPT4

Si desea obtener más información, puede visitar el sitio web oficial de openai: https://platform.openai.com/docs/models/gpt-4-and-gpt-4-turbo
Precios de los tokens
La API de OpenAI proporciona una variedad de tipos de modelos, cada uno disponible a distintos niveles de precios. Estos modelos varían en sus capacidades, con davinci posicionado como el más avanzado y ada como el más rápido. El coste de las solicitudes varía en función del modelo.
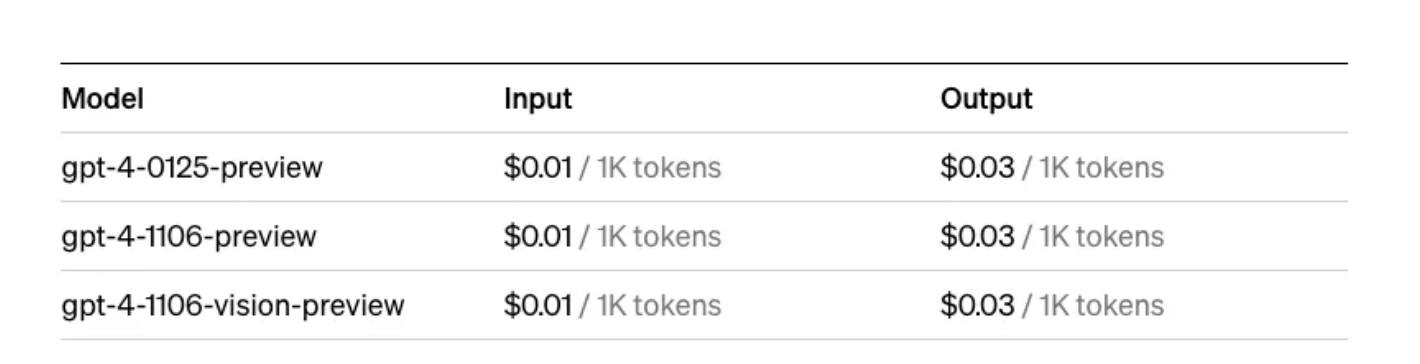
Por ejemplo, para el modelo GPT-4 Turbo, el coste es de 0,01 $/1K tokens para la entrada y 0,03 $/1K tokens para la salida.
Y según OpenAI:
Múltiples modelos, cada uno con diferentes capacidades y precios. Los precios son por 1.000 tokens. Puedes pensar en los tokens como trozos de palabras, donde 1.000 tokens son unas 750 palabras. Este párrafo son 35 tokens.
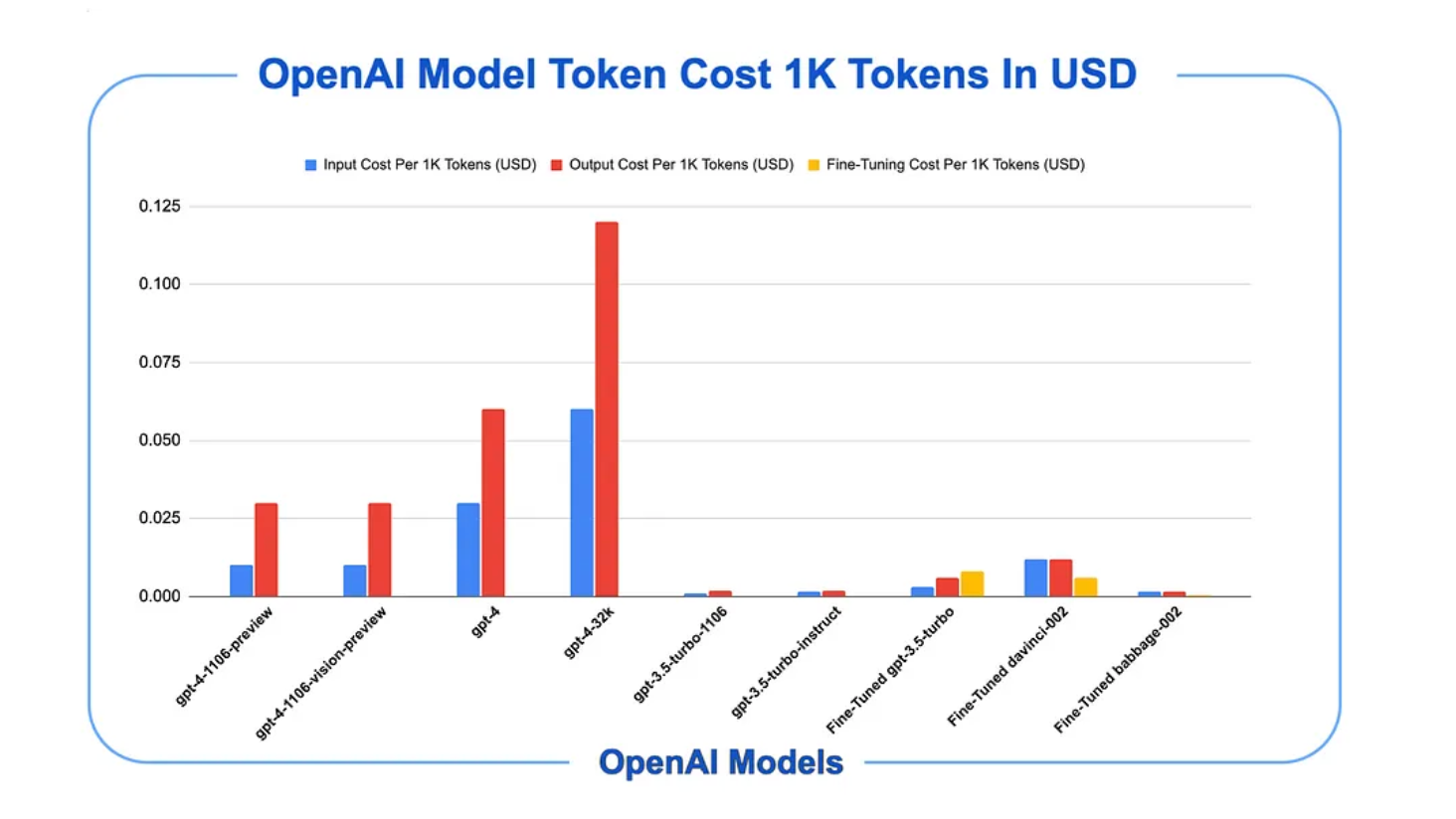
Cobus Greyling tiene un buen gráfico del coste de los tokens de OpenAI:
Calculadora de precios
Puede utilizar la siguiente "Calculadora de precios de OpenAI y otras API LLM" para realizar algunos cálculos:
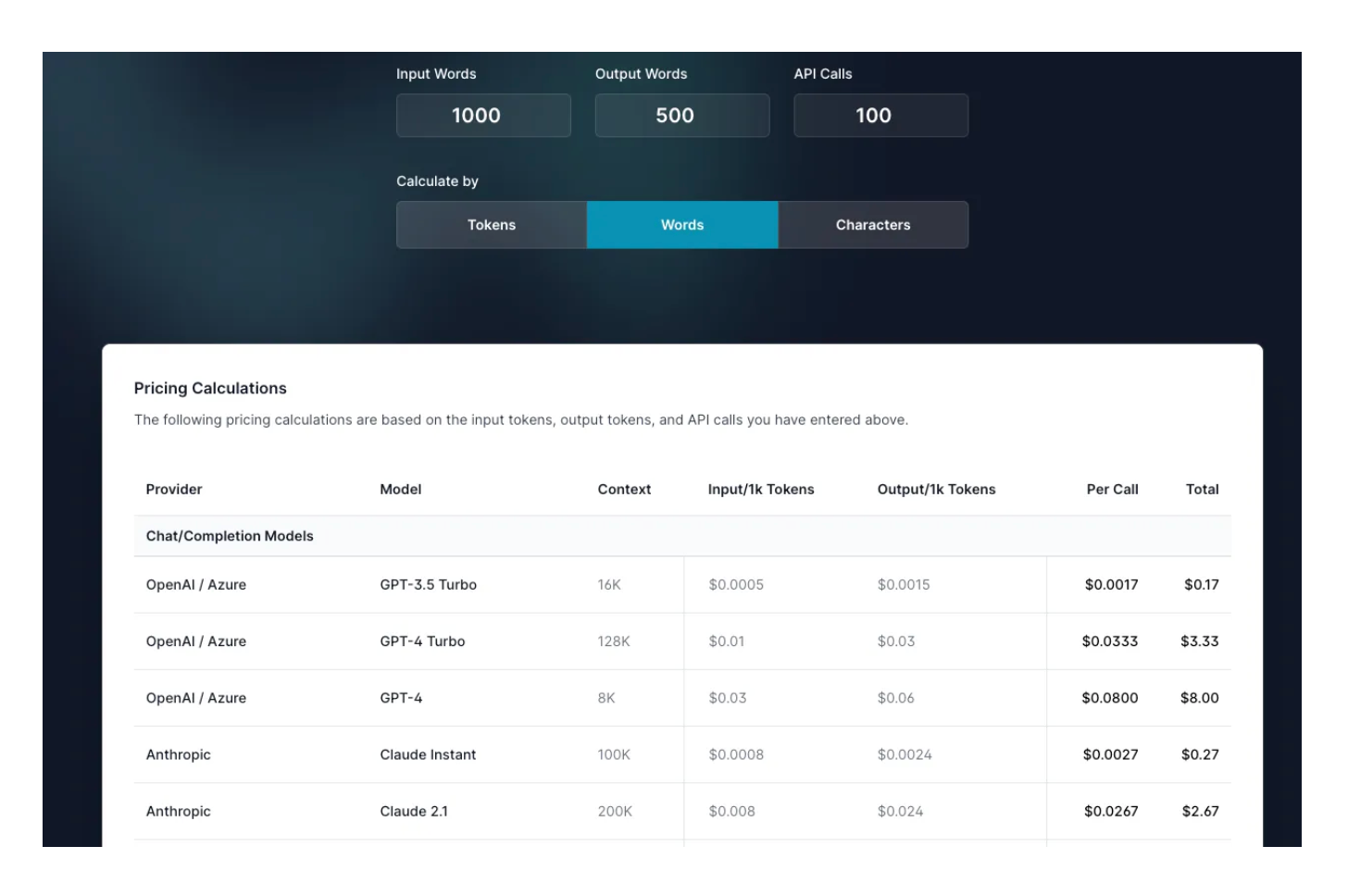
Lo anterior muestra el coste total de 1000 palabras de entrada, 500 palabras de salida y 100 llamadas a la API.
Buenas prácticas
Al utilizar tokens de OpenAI, adoptar las mejores prácticas puede ayudarle a maximizar la eficiencia, minimizar los costes y garantizar que sus interacciones con la API de OpenAI sean eficaces y seguras.
Estas son algunas de las mejores prácticas recomendadas:
Entender la economía de los tokens
Comprenda cómo se cuentan los tokens y qué constituye un token en el contexto de su uso. Conocer el recuento aproximado de tokens para distintas longitudes de entrada puede ayudarle a estimar el uso y los costes con mayor precisión.
Optimizar el diseño de las instrucciones
Diseñe sus instrucciones de forma que sean concisas pero lo suficientemente detalladas como para guiar al modelo hacia la generación del resultado deseado. Este equilibrio reduce el número de fichas utilizadas y aumenta la probabilidad de recibir respuestas útiles.
Utilice una gestión eficaz de los tokens
Controle el uso de tokens para evitar costes inesperados. Implemente alertas o límites si su plataforma o aplicación los admite para controlar su consumo.
Solicitudes por lotes cuando sea posible
Si su caso de uso lo permite, el procesamiento por lotes puede ser más eficiente que procesar las solicitudes de una en una. Este enfoque también puede suponer un ahorro de costes.
Aprovechar el modelo adecuado para la tarea
Elija el modelo más adecuado para su tarea. Mientras que los modelos más grandes, como Davinci, son más potentes, los modelos más pequeños, como Ada o Babbage, pueden ser más rentables para tareas que no requieren una comprensión profunda o creatividad, ahorrando así tokens.
Implementar caché para peticiones frecuentes
Si su aplicación realiza solicitudes repetidas con peticiones idénticas o similares, considere la posibilidad de almacenar en caché las respuestas para ahorrar tokens. Asegúrese de que la caché se gestiona de forma segura y respeta los requisitos de privacidad y protección de datos.
Proteja sus claves API
Proteja sus claves de API de OpenAI para evitar el uso no autorizado, que podría provocar el desperdicio de tokens y cargos inesperados. Implemente controles de acceso y rote las claves con regularidad.





