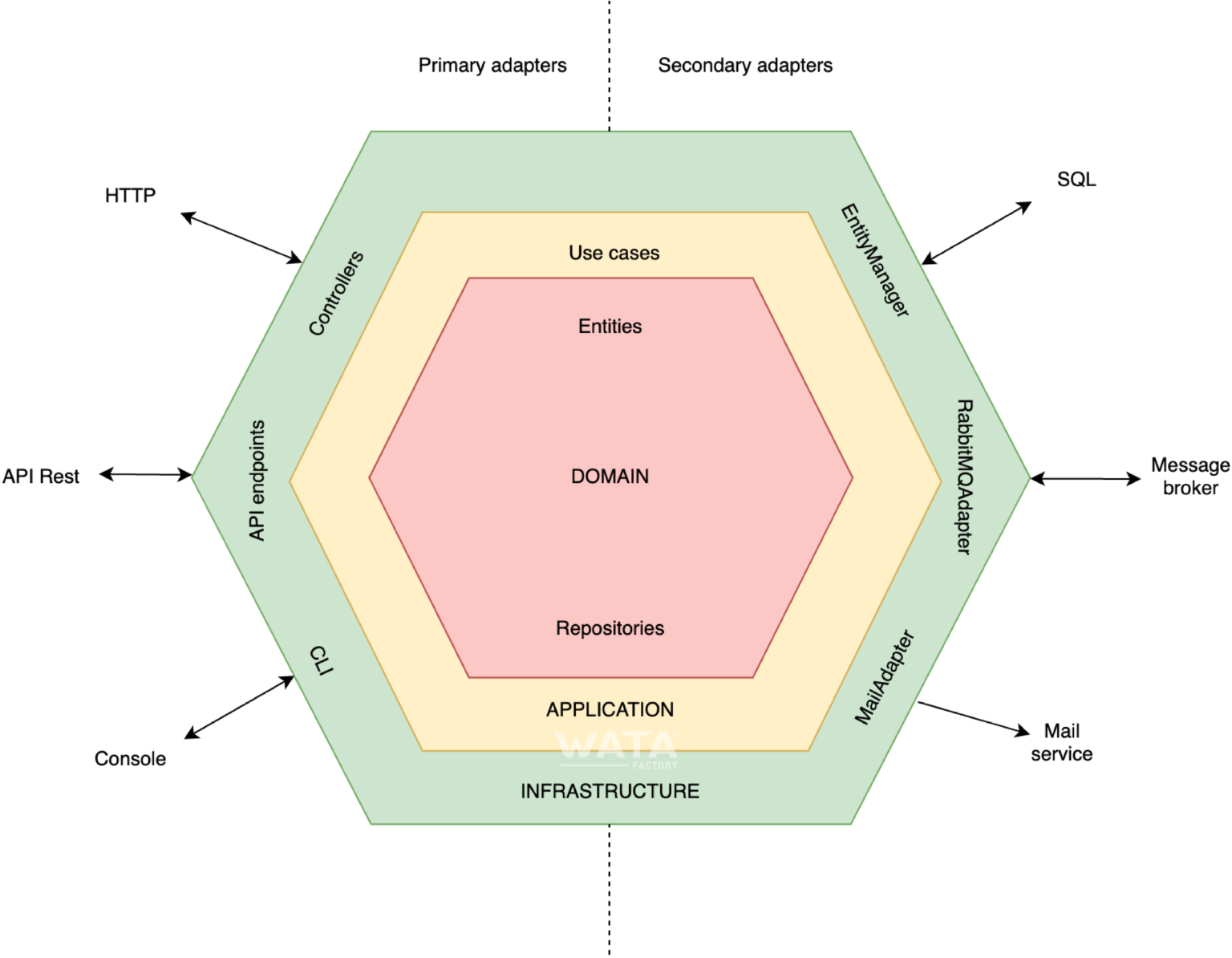
La intención original de la Arquitectura Hexagonal es permitir que una aplicación sea dirigida por igual por usuarios, programas, pruebas automatizadas o scripts por lotes, y que se desarrolle y pruebe de forma aislada de sus eventuales dispositivos de ejecución y bases de datos.
La arquitectura hexagonal junto con arquitectura de puertos y adaptadores es muy utilizada hoy en día, sin embargo la gente aun se confunde con el nombre y no conoce muy bien la diferencia entre ellos, cual es su valor añadido.
Esta arquitectura no es muy complicada de montar. Se basa en algunas reglas y principios sencillos. Exploremos estos principios para ver qué significan en la práctica.
Antes de que te ponerte al lio con la lectura de este blog, es importante que sepas que este post tiene una continuación , si gustas checarlo aquí tienes el link.
Definición
La arquitectura hexagonal es una arquitectura del software en la que se busca es separar el core lógico de la aplicación, dejarlo en el centro totalmente aislado del exterior, del cliente y de otras interacciones.
Partiendo un poco de la explicación de un grande como es Manuel Zapata, de quien si no le conoces o aún no vez su video te lo comparto para que también tengas una explicación desde otro enfoque.
Principios de la arquitectura hexagonal
La arquitectura hexagonal se basa en tres principios y técnicas:
- Separar explícitamente el lado del usuario, la lógica del negocio y el lado del servidor.
- Las dependencias van del lado del usuario y del lado del servidor a la lógica del negocio
- Aislamos los límites mediante el uso de Puertos y Adaptadores
Principio
Separar el lado del usuario, la lógica del negocio y el lado del servidor
El primer principio es separar explícitamente el código en tres grandes áreas formalizadas.
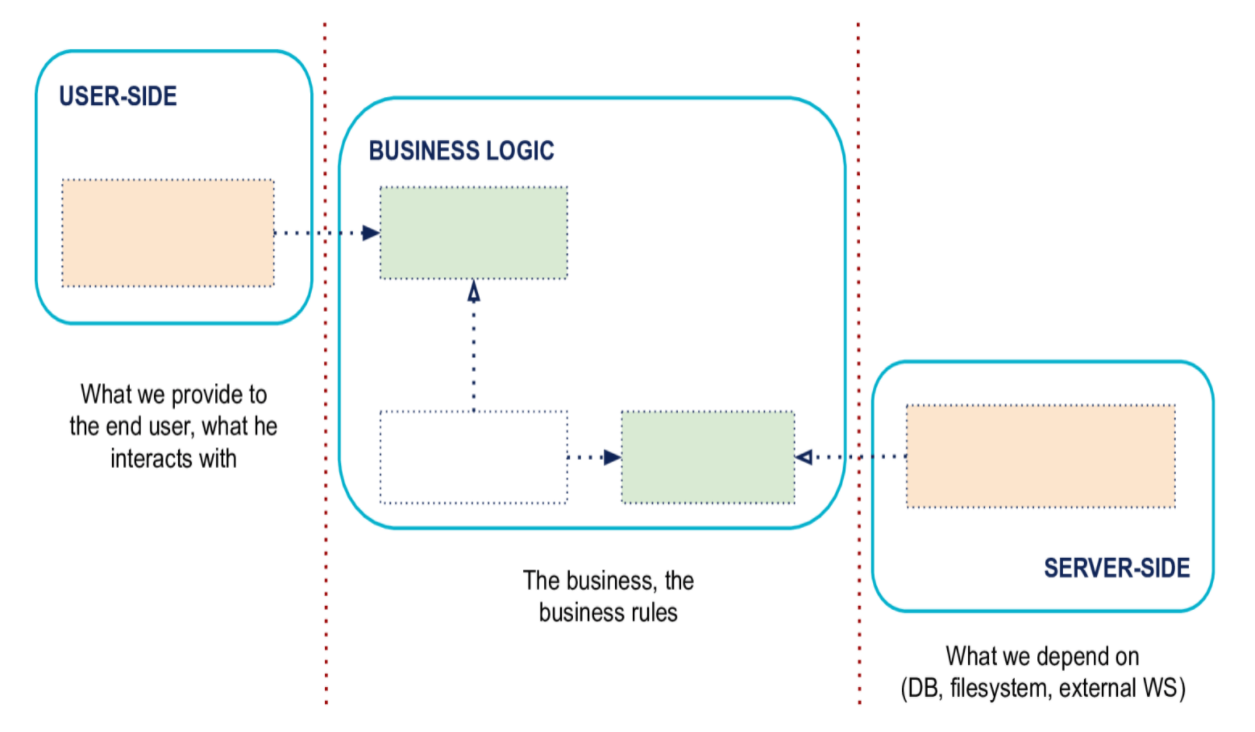
A la izquierda, el lado del usuario
Este es el lado a través del cual el usuario o los programas externos interactuarán con la aplicación.
Contiene el código que permite estas interacciones. Típicamente, su código de interfaz de usuario, sus rutas HTTP para una API, sus serializaciones JSON para los programas que consumen su aplicación están aquí.
Este es el lado donde encontramos a los actores que dirigen la Lógica de Negocio.
Nota: Alistair Cockburn también lo llama el Lado Izquierdo.
La Lógica de Negocio, en el centro
Esta es la parte que queremos aislar de los lados izquierdo y derecho. Contiene todo el código que concierne e implementa la lógica del negocio. El vocabulario de negocio y la lógica de negocio pura, que se relaciona con el problema concreto que resuelve tu aplicación, todo lo que la hace rica y específica está en el centro.
En el mejor de los casos, un experto en el dominio que no sepa codificar podría leer un trozo de código en esta parte y señalarte una incoherencia (¡es una historia real, son cosas que te pueden pasar!).
Nota: Alistair Cockburn también lo llama el Centro.
A la derecha, el lado del servidor
Aquí es donde encontraremos lo que tu aplicación necesita, lo que impulsa para funcionar. Contiene detalles esenciales de la infraestructura, como el código que interactúa con tu base de datos, hace llamadas al sistema de archivos, o el código que maneja las llamadas HTTP a otras aplicaciones de las que dependes, por ejemplo.
En este lado se encuentran los actores que son gestionados por la Lógica de Negocio.
Nota: Alistair Cockburn también lo llama el Lado Derecho.
Los siguientes principios permitirán poner en práctica esta separación lógica entre el Lado del Usuario, la Lógica de Negocio y el Lado del Servidor.
A través del siguiente gráfico partiremos a lo que es la explicación de la arquitectura hexagonal
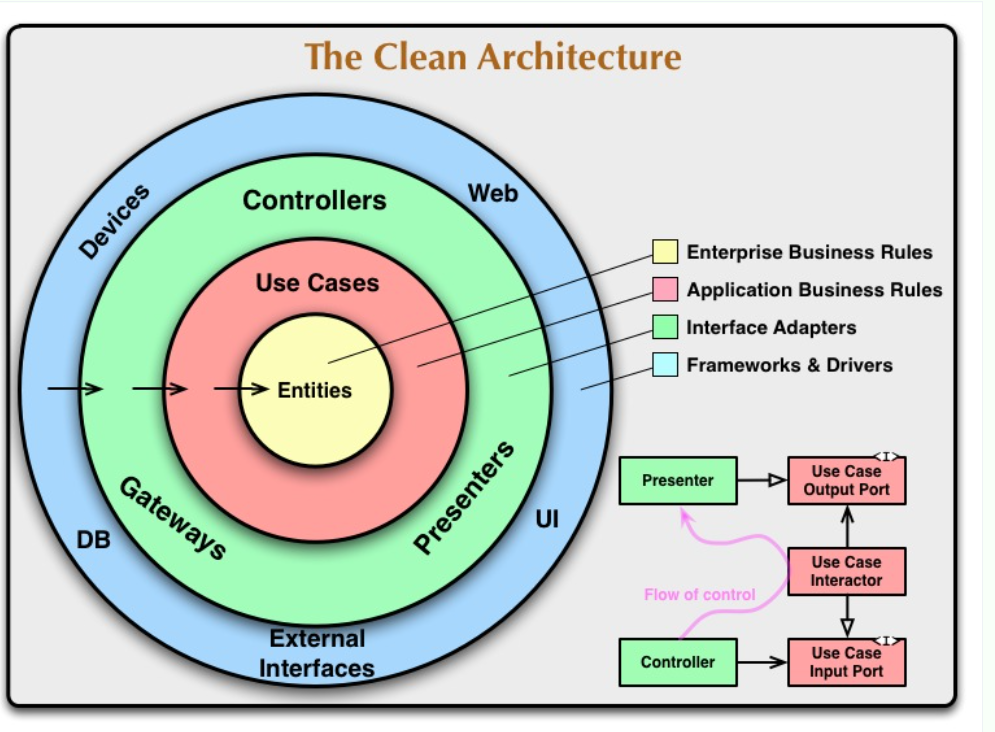
La regla de la dependencia
Los círculos concéntricos representan diferentes áreas del software. En general, cuanto más se adentra, más alto es el nivel del software. Los círculos exteriores son mecanismos. Los círculos interiores son políticas.
La regla principal que hace que esta arquitectura funcione es la regla de la dependencia. Esta regla dice que las dependencias del código fuente sólo pueden apuntar hacia adentro. Nada en un círculo interior puede saber nada en absoluto sobre algo en un círculo exterior.
En particular, el nombre de algo declarado en un círculo exterior no debe ser mencionado por el código en el círculo interior. Esto incluye funciones, clases, variables o cualquier otra entidad de software con nombre.
Del mismo modo, los formatos de datos utilizados en un círculo externo no deben ser utilizados por un círculo interno, especialmente si esos formatos son generados por un marco en un círculo externo. No queremos que nada en un círculo externo afecte a los círculos internos.
Entidades
Las entidades encapsulan las reglas de negocio de toda la empresa. Una entidad puede ser un objeto con métodos, o puede ser un conjunto de estructuras de datos y funciones. No importa siempre que las entidades puedan ser utilizadas por muchas aplicaciones diferentes en la empresa.
Si no tienes una empresa, y estás escribiendo una sola aplicación, entonces estas entidades son los objetos de negocio de la aplicación. Encapsulan las reglas más generales y de alto nivel. Son las menos propensas a cambiar cuando algo externo cambia. Por ejemplo, no se espera que estos objetos se vean afectados por un cambio en la navegación de la página, o en la seguridad.
Ningún cambio operativo en una aplicación concreta debería afectar a la capa de entidades.
Casos de uso
El software de esta capa contiene las reglas de negocio específicas de la aplicación. Encapsula e implementa todos los casos de uso del sistema. Estos casos de uso orquestan el flujo de datos hacia y desde las entidades, y dirigen a esas entidades para que utilicen sus reglas de negocio a nivel de empresa para lograr los objetivos del caso de uso.
No esperamos que los cambios en esta capa afecten a las entidades. Tampoco esperamos que esta capa se vea afectada por cambios en elementos externos como la base de datos, la interfaz de usuario o cualquiera de los marcos comunes. Esta capa está aislada de tales preocupaciones.
Sin embargo, esperamos que los cambios en el funcionamiento de la aplicación afecten a los casos de uso y, por tanto, al software de esta capa. Si los detalles de un caso de uso cambian, entonces algún código en esta capa se verá ciertamente afectado.
Adaptadores de interfaz
El software de esta capa es un conjunto de adaptadores que convierten los datos del formato más conveniente para los casos de uso y las entidades, al formato más conveniente para algún organismo externo como la Base de Datos o la Web.
Es esta capa, por ejemplo, es la que contendrá íntegramente la arquitectura MVC de una GUI. Los presentadores, las vistas y los controladores pertenecen a esta capa.
Los modelos son probablemente sólo estructuras de datos que se pasan de los controladores a los casos de uso, y luego de vuelta de los casos de uso a los presentadores y vistas.
Del mismo modo, los datos se convierten, en esta capa, de la forma más conveniente para las entidades y los casos de uso, en la forma más conveniente para cualquier marco de persistencia que se está utilizando, es decir, la base de datos.
Ningún código dentro de este círculo debe saber nada en absoluto sobre la base de datos. Si la base de datos es una base de datos SQL, entonces todo el SQL debería estar restringido a esta capa, y en particular a las partes de esta capa que tienen que ver con la base de datos.
También en esta capa está cualquier otro adaptador necesario para convertir los datos de alguna forma externa, como un servicio externo, a la forma interna utilizada por los casos de uso y las entidades.
Frameworks y Drivers.
La capa más externa se compone generalmente de marcos y herramientas como la base de datos, el marco web, entre otros. Generalmente no se escribe mucho código en esta capa, salvo el código de cola que se comunica con el siguiente círculo hacia adentro.
Esta capa es donde van todos los detalles. La Web es un detalle. La base de datos es un detalle. Mantenemos estas cosas en el exterior donde pueden hacer poco daño.
¿Sólo cuatro círculos?
No, los círculos son esquemáticos. Puedes encontrar que necesitas más que estos cuatro. No hay ninguna regla que diga que siempre hay que tener sólo estos cuatro. Sin embargo, la regla de la dependencia siempre se aplica. Las dependencias del código fuente siempre apuntan hacia adentro.
A medida que se avanza hacia el interior, el nivel de abstracción aumenta. El círculo más externo es un detalle concreto de bajo nivel. A medida que se avanza, el software se vuelve más abstracto y encapsula políticas de mayor nivel. El círculo más interior es el más general.
Cruzar los límites.
En la parte inferior derecha del diagrama hay un ejemplo de cómo cruzamos los límites del círculo. Muestra a los Controladores y Presentadores comunicándose con los Casos de Uso en la siguiente capa.
Observa el flujo de control. Comienza en el controlador, se mueve a través del caso de uso, y luego termina ejecutándose en el presentador. Observa también las dependencias del código fuente. Cada una de ellas apunta hacia el interior de los casos de uso.
Solemos resolver esta aparente contradicción utilizando el Principio de Inversión de Dependencias.
En un lenguaje como Java, por ejemplo, organizaríamos las interfaces y las relaciones de herencia de tal manera que las dependencias del código fuente se opongan al flujo de control en los puntos adecuados de la frontera.
Por ejemplo, consideremos que el caso de uso necesita llamar al presentador. Sin embargo, esta llamada no debe ser directa porque eso violaría la Regla de Dependencia: Ningún nombre en un círculo exterior puede ser mencionado por un círculo interior. Así que hacemos que el caso de uso llame a una interfaz (mostrada aquí como Puerto de Salida del Caso de Uso) en el círculo interior, y que el presentador en el círculo exterior la implemente.
La misma técnica se utiliza para cruzar todos los límites en las arquitecturas. Aprovechamos el polimorfismo dinámico para crear dependencias en el código fuente que se oponen al flujo de control, de manera que podamos cumplir con la Regla de Dependencia sin importar la dirección del flujo de control.
Qué datos cruzan los límites.
Normalmente los datos que cruzan los límites son estructuras de datos simples. Puedes usar structs básicos u objetos simples de transferencia de datos si quieres.
O los datos pueden ser simplemente argumentos en llamadas a funciones. O puedes empaquetarlos en un hashmap, o construirlos en un objeto.
Lo importante es que se pasen estructuras de datos aisladas y simples a través de los límites. No queremos hacer trampa y pasar entidades o filas de la base de datos. No queremos que las estructuras de datos tengan ningún tipo de dependencia que viole la Regla de Dependencia.
Por ejemplo, muchos frameworks de bases de datos devuelven un formato de datos conveniente en respuesta a una consulta. Podríamos llamarlo RowStructure.
No queremos pasar esa estructura de fila hacia adentro a través de un límite. Eso violaría la Regla de Dependencia porque forzaría a un círculo interno a saber algo sobre un círculo externo.
Por lo tanto, cuando pasamos datos a través de un límite, siempre es en la forma más conveniente para el círculo interno.
Conclusión
Cumplir con estas sencillas reglas no es difícil, y le ahorrará muchos dolores de cabeza en el futuro.
Al separar el software en capas, y ajustarse a la Regla de la Dependencia, crearás un sistema que es intrínsecamente comprobable, con todos los beneficios que ello implica.
Cuando alguna de las partes externas del sistema se vuelva obsoleta, como la base de datos, o el framework web, podrás reemplazar esos elementos obsoletos con un mínimo de complicaciones.





