
Traducción en español del artículo original de Rainer Hahnekamp "NgRx Best Practices Series: 2. Modularity" publicado el 11 diciembre 2021
En esta serie de artículos, estoy compartiendo las lecciones que he aprendido de la construcción de aplicaciones reactivas en Angular utilizando la gestión de estado NgRx.
En la Parte 1 explicó cómo llegué a usar NgRx. Segunda parte mostraba cómo añadirle funcionalidad de caché. Aquí, veremos la gestión de estados desde un punto de arquitectura.
El código fuente está disponible en GitHub.
Si quieres leer más contenido acerca de estos temas visita mi blog
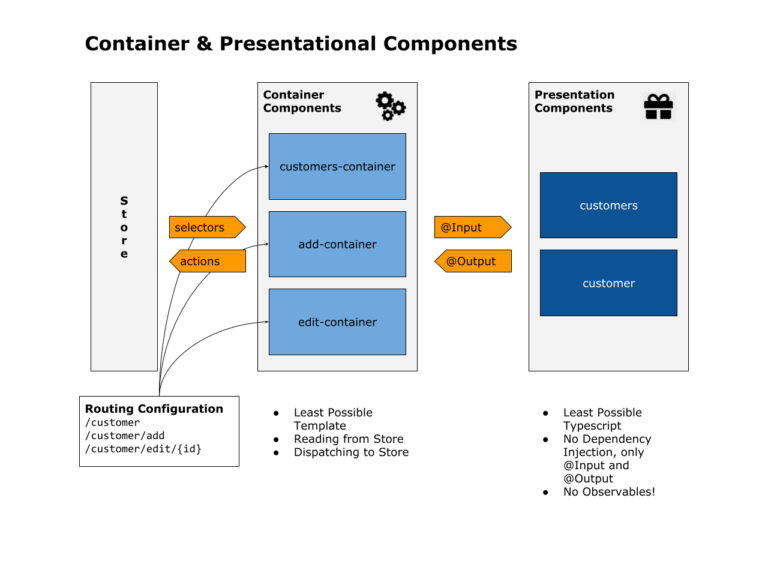
Modularidad: Contenedores, Presentación y Estado
Este patrón arquitectónico integra la gestión del estado en la conocida arquitectura de contenedor/presentación.
Creamos un módulo sólo para el código relevante para NgRx.
A continuación, dividimos nuestros componentes en otros dos módulos. El primero contiene los componentes del contenedor que son responsables de la comunicación con el estado.
El segundo contiene los componentes de presentación. Son responsables de la representación.
Tener tres módulos distintos con responsabilidades claras mejora enormemente la capacidad de mantenimiento de nuestra aplicación.
El problema subyacente no es nuevo y es muy conocido en otras áreas de la programación. Una clase/función/componente hace demasiadas cosas.
Si vemos un componente que se extiende por más de 100 líneas de código, probablemente hemos encontrado un ejemplar. Debido a ese tamaño, es difícil entender rápidamente su propósito.
Esto hace que sea menos mantenible, y comprobable. Va en contra del principio de responsabilidad única.
Muy a menudo, encontramos lo mismo en el mundo Angular. Siempre hay un componente que contiene código no trivial junto con el HTML y el CSS.
Ejemplos de código no trivial o "lógica" pueden ser el envío de acciones a NgRx, el uso del router, o alguna interacción con servicios.
Es importante saber que Comunicarse con NgRx es una cosa, renderizar es otra. No hagas todo eso en un solo componente.
Un componente debe hacer sólo una cosa. Es renderizar o ejecutar la "lógica". Esa es la idea básica detrás del patrón de contenedores y componentes de presentación.
Así que tenemos un llamado componente de presentación que es responsable de la visualización. Consiste principalmente en HTML y CSS.
En nuestro ejemplo, esto significaría mostrar la lista o el formulario del cliente.
El componente no sabe cómo obtener datos de NgRx. Ni siquiera sabe si se utiliza NgRx.
Sólo obtiene su entrada a través de @Input(). Tampoco sabe qué debe ocurrir cuando el usuario hace clic en un botón de envío.
Sólo emite un evento a través de @Output() y espera que alguien en la jerarquía del componente sepa qué hacer.
export class CustomerComponent {
formGroup = new FormGroup({});
@Input() customer: Customer | undefined;
@Output() save = new EventEmitter<Customer>();
@Output() remove = new EventEmitter<Customer>();
fields: FormlyFieldConfig[] = [
// form configuration
];
submit(customer: Customer) {
if (this.formGroup.valid) {
this.save.emit(this.formGroup.value);
}
}
handleRemove(customer: Customer) {
if (confirm(`Really delete ${customer}?`)) {
this.remove.emit(this.customer);
}
}
}
Ese alguien es el componente contenedor.
Es consciente del contexto. Sabe cómo tratar con NgRx, qué selectores son necesarios, cómo acceder a la ruta, entre otras. No sabe cómo se visualizan los datos. Simplemente los obtiene, los transforma y los transmite.
Un componente contenedor normalmente no tiene CSS, sólo un HTML mínimo. Ese HTML contiene el selector del componente de presentación subyacente.
El componente contenedor tampoco debe tener ningún enlace de entrada o salida. Como componente consciente del contexto, conoce su lugar en la aplicación, de dónde obtener todos los datos, y a quién llamar una vez que se produce un evento.
@Component({
selector: 'eternal-edit-customer',
template: ` <eternal-customer
*ngIf="customer$ | async as customer"
[customer]="customer"
(save)="this.submit($event)"
(remove)="this.remove($event)"
></eternal-customer>`,
})
export class EditCustomerComponent implements OnInit {
customer$: Observable<Customer> | undefined;
constructor(private store: Store, private route: ActivatedRoute) {}
ngOnInit() {
this.customer$ = this.store
.select(
fromCustomer.selectById(Number(this.route.snapshot.params.id || ''))
)
.pipe(
map((customer) => {
return { ...customer };
})
);
}
submit(customer: Customer) {
this.store.dispatch(
CustomerActions.update({ customer })
);
}
remove(customer: Customer) {
this.store.dispatch(
CustomerActions.remove({ customer })
);
}
}
Existen términos alternativos para este patrón. Algunos términos muy comunes son componente smart/dump.
Por supuesto, no siempre es posible adherirse a estas reglas estrictas. Habrá ocasiones en las que un componente de presentación necesite utilizar la inyección de dependencias de Angular.
Por ejemplo, si quiere mostrar un formulario (como la pantalla de detalles del cliente), debería inyectar el FormBuilder.
Lo mismo ocurre con los componentes contenedores. Puede haber casos de uso válidos en los que reciba datos vía @Input de un componente padre. Pero, por favor, tratemos de evitar tener múltiples niveles de componentes contenedores anidados vinculados entre sí a través de la vinculación de propiedades.
¿Qué pasa con el State?
Dividir los componentes es la parte difícil. Lo que viene después es fácil. Los tipos de componentes obtienen sus propios módulos.
Podemos llamar a los módulos con los componentes contenedores "feature" y al de las presentaciones "ui". Este es el esquema de nomenclatura que también utiliza nx (ver más abajo).
Lo mismo ocurre con el estado. Movemos todo el código NgRx relevante a un tercer módulo que se llama simplemente "data" (nx naming).
Casos especificos
Una ventaja inmediata perceptible es que ahora podemos reutilizar el mismo componente de formulario pero con un comportamiento diferente.
El componente de presentación con el formulario es el mismo, independientemente de si se trata de editar o añadir un cliente.
Los componentes contenedores se encargan de las diferencias. Dependiendo de las diferencias entre la edición o la adición, podemos tener dos de ellos.
Así que terminamos con tres componentes. A primera vista puede parecer un exceso de trabajo. No es el caso.
Los componentes son muy pequeños y sabemos inmediatamente dónde buscar cuando queremos cambiar la lógica para editar o añadir un cliente (componentes contenedores) o si queremos simplemente cambiar el formulario en sí (componente de presentación).
Pruebas más fáciles
Esta estricta separación también tiene otras ventajas. Podemos crear fácilmente pruebas unitarias para el componente contenedor.
Crear test unitarios en el front es muy difícil. El problema es la mezcla entre el código real y el HTML/CSS. Con los componentes contenedores, sólo queda el código.
Es una clase normal con métodos y podemos escribir pruebas unitarias normales contra ella como lo haríamos en el backend.
Hay que decidir si es necesario probar la parte de código del componente de presentación. Podemos omitirla por completo o cambiar a una técnica de prueba especial como la Regresión Visual.
Esta decisión dependerá muy probablemente de nuestro tipo de aplicación y de sus requisitos de calidad.
¿Más código = mejor?
Esto es para los lectores que acaban de empezar su carrera de programación: Dividir los componentes hace que nuestra base de código sea más fácil de mantener.
Para los desarrolladores principiantes, esto puede parecer contraintuitivo. Acabamos de hacer dos componentes o incluso tres en lugar de uno.
Junto con toda la jerga de los componentes (declaración de clase TypeScript, metadatos @Component), podríamos terminar teniendo incluso más líneas de código que antes. ¿Por qué debería ser mejor?
El aumento del tamaño del código y una mejor mantenibilidad no son mutuamente excluyentes. Esto es normal. No eliminamos la complejidad, sólo la dividimos en unidades más pequeñas.
Es más fácil para nosotros si podemos trabajar en tres pequeños problemas en lugar de un gran problema. O dicho de otro modo, es más fácil trabajar con 3 archivos con 45 líneas de código en lugar de un archivo con 120 líneas de código.
Las clases son más cortas y las responsabilidades están claras. Si tenemos que buscar errores con el estado, buscamos en el módulo de estado. Si el diseño está roto, vamos al módulo de interfaz de usuario.
Si el estado está bien pero los datos erróneos terminan en la UI, probablemente sea un error en el componente contenedor.
Forzando reglas con Nx
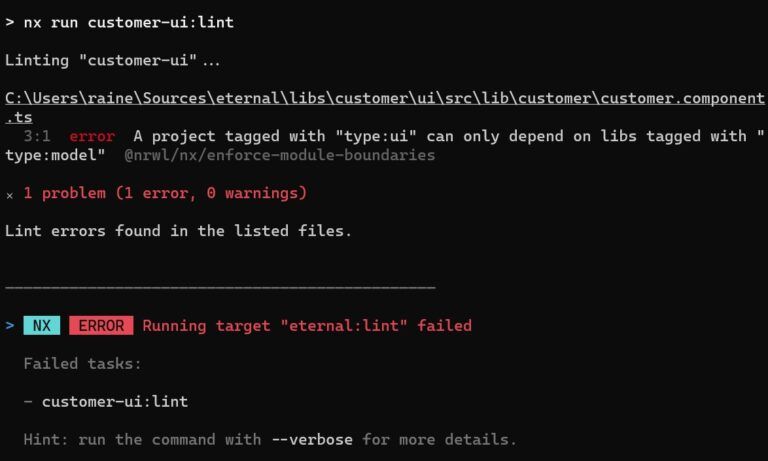
Sólo permitimos que los componentes contenedores hablen con NgRx. ¿Cómo se puede imponer esto?
Usamos nx, una extensión para el CLI de Angular, y usamos su función para definir reglas de dependencia. Ya está hecho.
A partir de ahora, cada vez que un componente de presentación intente usar algo del módulo de datos (=módulo relacionado con NgRx), obtendremos un error de linting y la compilación se romperá.
Pero eso no es todo. Podemos ir más allá. En NgRx, queremos que ciertas acciones sólo sean llamadas por los componentes del contenedor.
Por ejemplo: Si usamos el patrón LoadStatus, entonces debe estar prohibido que cualquier componente fuera de NgRx despache el método load (o incluso loaded).
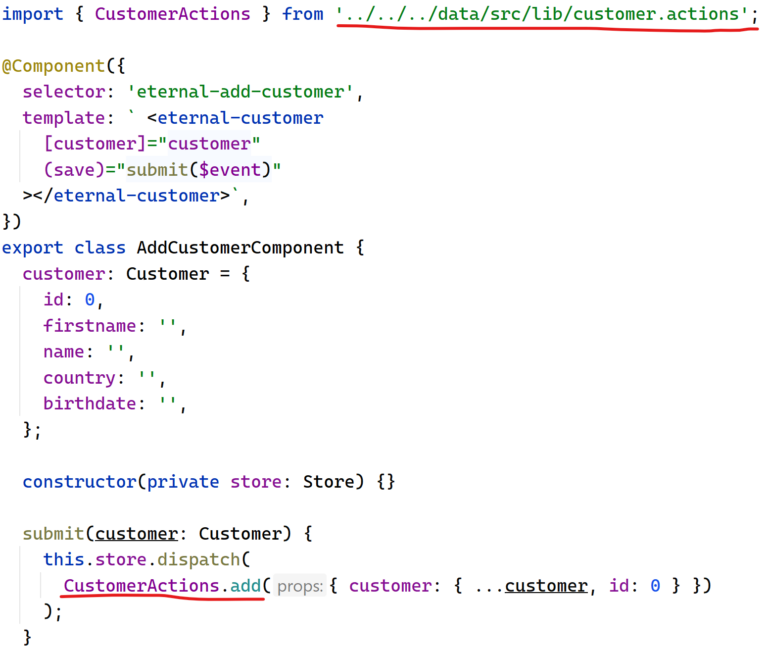
Para conseguirlo, el módulo de datos sólo exporta una lista limitada de acciones. Esta lista se define en su index.ts`. Cualquier componente puede seguir accediendo a una acción no exportada haciendo referencia directa al archivo de acciones de NgRx.
Pero esto se llama una importación profunda y nx intervendría aquí de nuevo y lanzaría un error de linting.
const removed = createAction(
'[CUSTOMER] Removed',
props<{ customers: Customer[] }>()
);
export const CustomerActions = {
get,
load,
loaded,
add,
added,
update,
updated,
remove,
removed,
};
export const PublicCustomerActions = {
get,
add,
update,
remove,
};
Acciones NgRx exponiendo un conjunto para uso interno y otro para público
export * from './lib/customer-data.module';
export { PublicCustomerActions as CustomerActions } from './lib/customer.actions';
export * from './lib/customer.selectors';
index.ts exponiendo sólo las acciones NgRx definidas en PublicCustomerActions
Los modelos
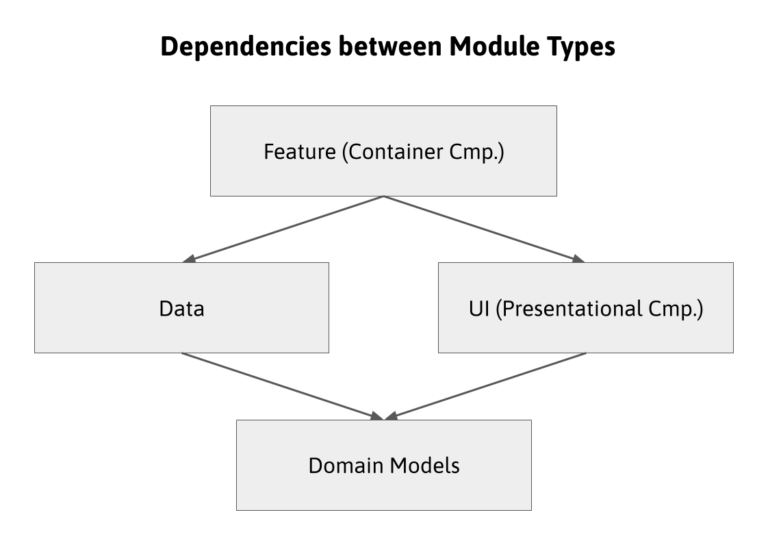
¿En cuál de los tres módulos debemos poner las interfaces que definen nuestros modelos de dominio? En ninguno. Si ponemos las interfaces en el módulo de estado o contenedor, nuestros componentes de UI no pueden tenerlas como valores de entrada o salida.
A menos que nuestra aplicación sólo tenga una interfaz de usuario genérica, esto sería un problema.
Tampoco podemos añadir a la UI porque no queremos acoplar la gestión del estado con nuestra UI. Tenemos los componentes contenedores como mediadores.
El mejor lugar para los modelos sería un módulo propio en el que nuestros tres módulos tengan una dependencia.
El futuro
La siguiente parte de esta serie tratará un tipo de problema muy común. Queremos redirigir al usuario después de que un efecto haya enviado con éxito una solicitud al backend.
Otro caso de uso similar, basado en el mismo tipo de problema, es mostrar un mensaje de notificación después de una comunicación con el backend.
¿Quien debería hacerlo el effect, action? ¿Sería mejor en un componente? ¡Sigue atento para conocer la respuesta!