
📌 Este post hace uso de las siguientes tecnologías
Aca tienes la documentación para crear tu propio chatbot

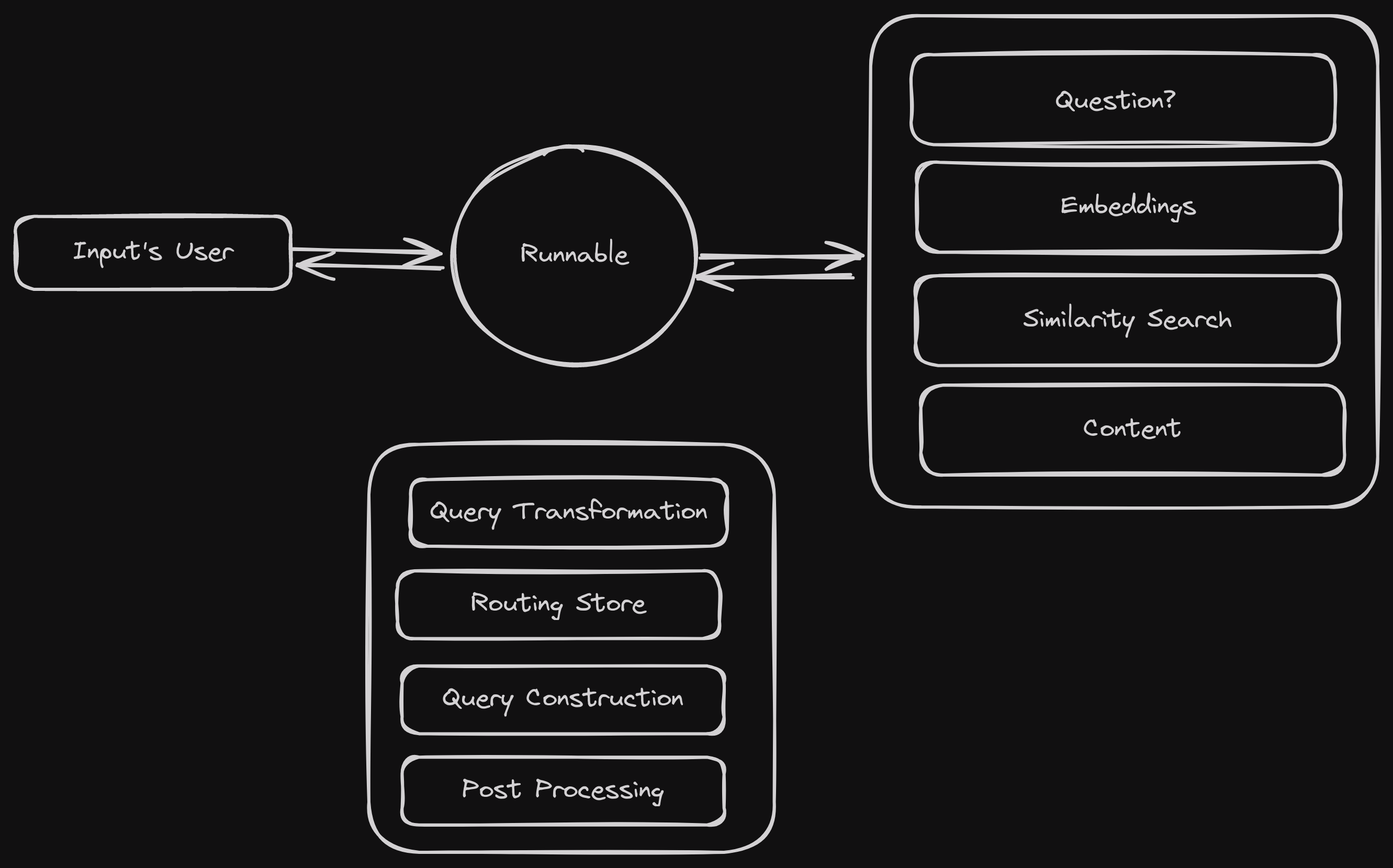
¿Qué es RAG (Retrieval Augmented Generation)?
RAG: es definido como un sistema que envuelve una pregunta, (a menudo realizada por un usuario) para determinar lo que el sistema debe recuperar.
RAG se divide en 2 procesos:
1 - Recuperación de la información desde algún DataSource o Source, esto quiere decir desde cualquier lugar que necesitemos recuperarla usando herramientas a fines con este propósito.
2 - Procesamiento de la información recuperada para pasarla a nuestro LLM (Large Language Model), el cual lo construye en formato prompt como el que conocemos y le hemos pasado a ChatGPT.
Para no caer en complejidades de papers que explican de una manera técnica y precisa el funcionamiento actual de un chat conversacional nos quedaremos con a idea que para lo que queremos construir necesitamos 4 cosas importantes:
- El Dataset; este puede ser un json, un csv o algún fichero limpio y definido.
- El Embedding o capa de vector; es quien hace las matemáticas por nosotros y computa palabras y sub-palabras en números flotantes.
- El Modelo; Nuestro bien conocido OpenAi, Cohere o incluso LlamaCPP (META).
- El vectorStore; esta es una base de datos que funciona muy diferente a las que conocemos pero que para nada muy lejos de lo que entendemos como funciona una base de datos.
Para este pequeño proyecto seguimos una publicación reciente de Qdrant
Dataset
Son nuestros datos populados, tanto si tenemos algún tipo de servicio el cual ofrecemos mediante asesorías, o si simplemente tenemos mucha información que ofrecemos a nuestros clientes casi siempre respondiendo las mismas preguntas.
Embeddings o Vectores
Los embeddings son matrices ya computadas por librerías predefinidas las cuales son necesarias para poder hacer búsquedas semánticas, similares, full text o incluso mejor búsquedas Híbridas
Nos enfocaremos en la ultima, y para la cual necesitamos vectores esparcidos esto quiere decir que la mayoría de valores en la matriz son ceros
//Nuestros vectores quedarian de esta manera:
//para una palabra como hola mundo
{"indices":[780306906],"values":[1.0]}
//pero nuestro vectorStore lo necesitaria de esta forma:
...
vector: {
"text": {"indices":[780306906],"values":[1.0]}
}
...
// Esta es la manera en que Qdrant hace busqueda por vectores esparcidos.📢 Para la obtención o conversión de nuestros textos a vectores usaremos una pequeño API realizada en Python dado que para nuestro objetivo solo tenemos librerías hechas en ese lenguaje, pero no te asustes te dejare el código para que copies y pegues
# Guarda este fichero como main.py
from typing import Union
from pinecone_text.sparse import BM25Encoder
from pinecone_text.dense import SentenceTransformerEncoder
tokenizer_dense = SentenceTransformerEncoder("sentence-transformers/all-MiniLM-L6-v2")
tokenizer_sparse = BM25Encoder.default()
from fastapi import FastAPI
app = FastAPI()
@app.get("/")
def read_root():
return {"Hello": "World"}
@app.get("/dense/{text}")
def read_item(text: str):
return tokenizer_dense.encode_queries(text)
@app.get("/sparse/{text}")
def read_item(text: str):
return tokenizer_sparse.encode_queries(text)Para correr la Api de arriba necesitas primero instalar estos paquetes
# Crea tu entorno virtual y enciendelo
virtualenv env
source env/bin/activate
# Instala los paquetes necesarios
pip install pinecone-text fastapi "uvicorn[standard]"
# Corre la api
uvicorn main:app --reload --port 8090
# main: es tu archivo main.py
# app: significa que es tu archivo principal
# --reload: es un watch que observa si haces algun cambio poder recargar la api
# --port: (opcional) pero por si tienes el 8000 ocupado no lo olvides ;)Si Llegaste acá significa que tienes tu API ya montada. proseguimos 😎
clona este repo:
 Elimeleth
Elimelethmkdir chatbot
cd chatbot
git init
gh repo clone Elimeleth/qdrantQdrant como vectorStore
Así como existen muchos colores, existe muchos vectorStore pero usaremos Qdrant y así aprendemos algo nuevo jeje
No hace falta instalar nada en nuestro sistema dado que Qdrant tiene su imagen oficial de Docker
🤯🤯🤯🤯 ¿Qué es DOCKER?????????
A efectos prácticos Docker es un gestor de repositorios basados en imágenes pero para un amplio entendimiento te dejo esta pequeña explicación.
Proseguimos …
docker run --rm -d -p 6333:6333 \
-v $(pwd)/qdrant_storage:/qdrant/storage:z \
qdrant/qdrant:v1.7.3#si haces ahora curl a tu localhost:6333 te deberia mostrar algo como esto:
#{"title":"qdrant - vector search engine","version":"1.7.3"}
curl localhost:6333/Qdrant funcionando como retriever
En la carpeta src/retriever.js veras una clase llamada QdrantRetriever la cual es una extensión de la clase QdrantVectorStore acoplada por la librería langchain
Extendí la clase con el propósito de mostrar el funcionamiento de los vectores esparcidos en Qdrant el cual, aunque es cierto que solo extendiendo la funcionalidad del embedding podríamos llegar al mismo resultado, todo es mejor cuando se desglosa el por que de las cosas.
❓ La clase cuenta con 4 funciones sobre escritas las cuales son:
similaritySearchVectorWithScore: busca mediante la computación de los embeddings la similitud entre valores existentes en la Base de datos.addDocuments: Agrega un nuevo corpus de datos a la base de datos usandoaddVectorspor debajo.addVectors: método de creación de nuevos objetos en la base de datosensureCollection: se asegura de recrear la coleccion si esta no existiera.
Una vez entendemos el funcionamiento que nos provee langchain en la clase QdrantVectorStore podemos hacer tanto como nuestra creatividad nos permita y esto ya es algo asombroso de creer!
/*
Busqueda de valores similares necesita solo un valor requerido el cual es vector
*/
/**
*@example
* retriever.similaritySearchVectorWithScore({indices: [32312321], values: [1.0]})
*
*/
async similaritySearchVectorWithScore(vector, k, filter) {
/*
vector puede ser number[][]
or
{
indices: number[],
values: number[],
}
*/
if (!vector) {
return [];
} // En caso el vector sea vacio retornamo un array vacio
if (vector.indices && vector.values) vector = {
name: 'text',
vector
} // En caso el vector sea un objeto con las key indices y values lo convertimos a como lo necesita Qdrant
const results = await this.client.search(this.collectionName, {
vector, //
limit: k,
filter,
// A efectos de optimizacion el parametro params puede llegar a acelerar las busquedas
params: {
quantization: {
rescore: false
},
hnsw_ef: 128,
exact: false
},
});
// retornamos un documento
const result = results.map((res) => [
new Document({
metadata: res.payload.metadata,
pageContent: res.payload.content,
}),
res.score,
]);
return result;
}/*
esta funcion recibe un array de objetos y opciones del documento a crear
mapea el contenido de cada pagina para crear una matriz de vectores y pasarla a nuestra funcion
encargada de adjuntar los vectores en nuestra base de datos.
*/
async addDocuments(batches, documentOptions) {
const documents = await this.build_documents(batches)
const texts = documents.map(doc => doc.pageContent);
await this.addVectors(await this.embeddings.embedDocuments(texts), documents, documentOptions);
}async addVectors(vectors, documents, documentOptions) {
if (vectors.length === 0) {
return;
}
const points = vectors.map((vector, idx) => ({
id: v4() // usamos uuid como creador de identificadores,
vector: (vector?.indices && vector?.values) ? { 'text': vector } : vector,
payload: {
content: documents[idx].pageContent,
metadata: documents[idx].metadata,
customPayload: documentOptions?.customPayload[idx],
},
}));
try {
// insertamos nuestros vectores en la base de datos
await this.client.upsert(this.collectionName, {
wait: true,
points,
});
// volvemos a actualizar nuestra collecion con los parametros establecidos por la documentacion de Qdrant
await this.client.updateCollection(
this.collectionName, {
"optimizers_config": {
indexing_threshold: 20000,
memmap_threshold: 20000
}
});
// creamos un full text search mediante un payloadIndex
await this.client.createPayloadIndex(this.collectionName, {
field_name: "text",
field_schema: "text"
});
console.log("upsert done!")
}
catch (e) {
const error = new Error(`${e?.status ?? "Undefined error code"} ${e?.message}: ${e?.data?.status?.error}`);
throw error;
}
}/*
Esta es nuetra primera funcion la cual se asegura que la colección siempre exista
*/
async ensureCollection() {
const response = await this.client.getCollections();
const collectionNames = response.collections.map((collection) => collection.name);
if (!collectionNames.includes(this.collectionName)) {
await this.client.recreateCollection(this.collectionName, {
vectors: {
distance: 'Cosine',
size: (await this.embeddings.embedQuery('foo'))?.length || 384,
quantization_config: {
// para logra un low memory footprint o bajo consumo usamos el tipo de quantization scalar
// una quantization es convertir grandes dimensiones en tipos de enteros mas pequenos para que pueda caber mas vectores en nuestra memoria sin llegar a un overhead
scalar: {
type: "int8",
quantile: 0.99,
always_ram: true,
}
},
},
"optimizers_config": {
indexing_threshold: 0,
memmap_threshold: 0
},
// Aqui ocure la magia, como nos explica la documentacion sobre los vectores esparcidos
sparse_vectors: {
"text": {
index: {
on_disk: false
}
}
}
});
console.log('Collection created successfully')
}
console.log('Collection found: ' + this.collectionName)
}Si llegaste hasta acá, te espero en el próximo episodio! <3





