
Familiaricémonos primero con algunos términos arquitectónicos
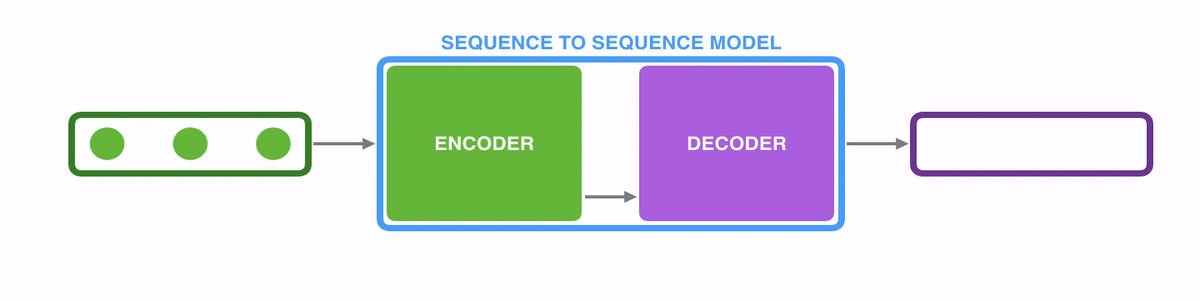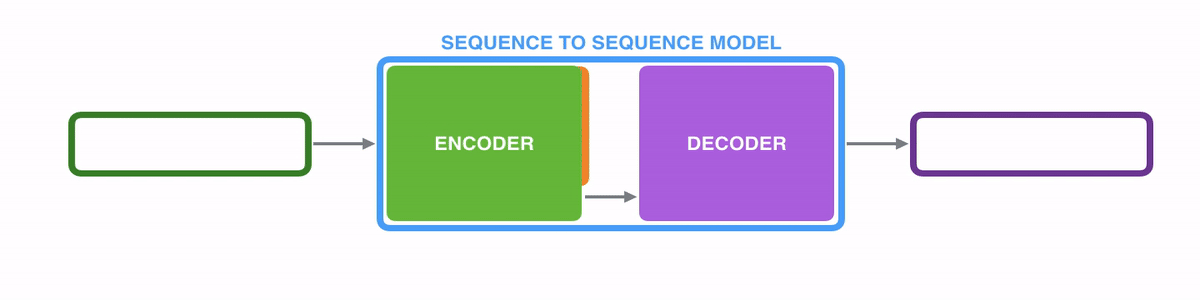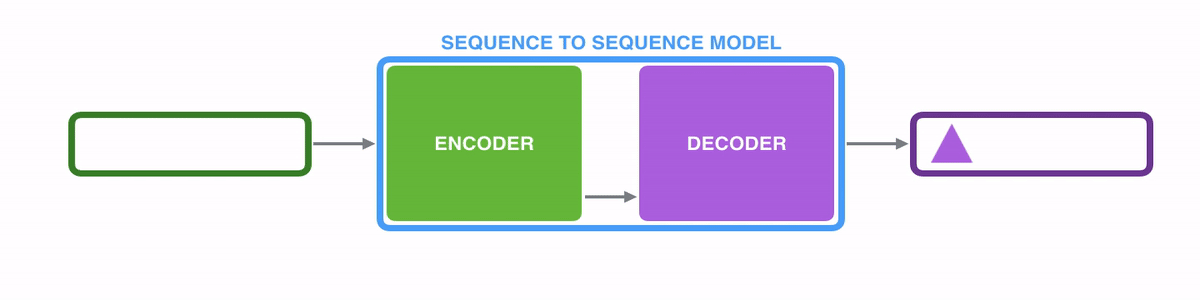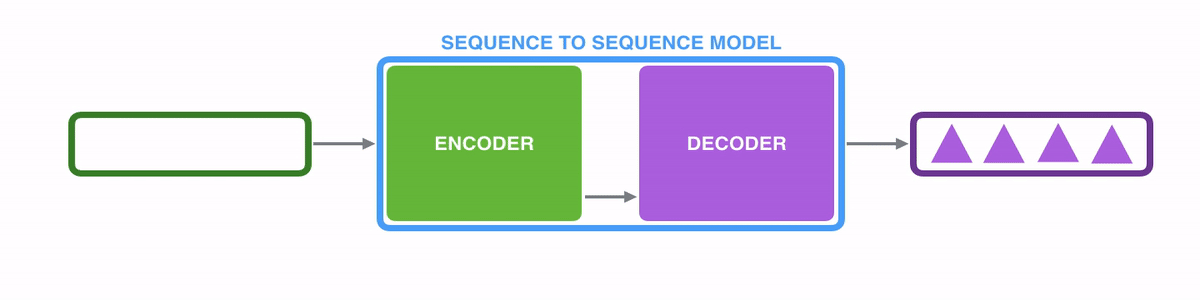
Codificador y decodificador
- Codificador: Procesa y transforma los datos de entrada en una representación condensada que captura la información esencial. En una tarea de traducción, un codificador toma una frase en inglés y la convierte en un vector que representa sus características lingüísticas y su significado.
- Decodificador: Toma la representación codificada y genera una salida, a menudo en una forma diferente. En la misma tarea de traducción, el descodificador toma la representación codificada de una frase en inglés y genera su equivalente en francés.
Si tu quieres aprender más acerca de inteligencia artificial y sus diferentes usos, te dejo LOS CURSOS
Modelos sólo codificador
- Ejemplo: Modelos basados en BERT
- Enfoque de preentrenamiento: Modelado de lenguaje enmascarado (MLM)
Caso práctico
Tareas que requieren una comprensión profunda de los datos de entrada. Estos modelos son eficaces para la clasificación, el análisis de sentimientos y la extracción de información.
Modelos basados únicamente en decodificadores
- Ejemplo: GPT, XLNet
- Enfoque de preentrenamiento: Predicción del siguiente token
Caso práctico
Tareas generativas. Predicen el texto siguiente basándose en el contexto proporcionado de forma autorregresiva. Su función principal es la generación de resultados sin una fase de codificación separada.
Modelos de codificador-decodificador
- Ejemplo: T5, BART, Google Gemini (probablemente)
- Preentrenamiento: Dependiente de la tarea

Caso práctico
Tareas que implican tanto la comprensión como la generación de datos. Primero codifican una secuencia de entrada en una representación interna y luego decodifican esta representación en una secuencia de salida.
Si comparamos la finalidad de estas arquitecturas, en primer lugar podemos excluir fácilmente los modelos basados únicamente en codificadores: Suelen estar preentrenados con MLM y no ayudan necesariamente a generar la salida.
En cambio, los de sólo decodificador tienen mucho sentido: Se utilizan para generar salidas y están preentrenados en tareas de predicción de token siguiente, que es exactamente la tarea de la mayoría de los LLM.
La cuestión se reduce realmente a la arquitectura de sólo decodificador frente a la de codificador-decodificador:
Teniendo un componente decodificador y, por tanto, capacidad generativa, ¿tener componentes codificadores adicionales no sería una ayuda?
Decodificador causal (CD) frente a codificador-decodificador (ED)
El rendimiento del decodificador solo, también denominado decodificador causal, frente a los modelos codificador-decodificador se ha estudiado durante mucho tiempo. Uno de los primeros trabajos es el titulado What Language Model Architecture and Pretraining Objective Work Best for Zero-Shot Generalization? de Wang et al, publicado en ICML 2022.
En este estudio, los investigadores compararon varias combinaciones de arquitectura y enfoques de preentrenamiento. Lo que descubrieron fue lo siguiente:
"Nuestros experimentos muestran que los modelos de solo decodificador causal entrenados en un objetivo de modelado de lenguaje autorregresivo exhiben la generalización de disparo cero más fuerte después de un preentrenamiento puramente autosupervisado".
"Sin embargo, los modelos con visibilidad no causal en su entrada entrenados con un objetivo de modelado del lenguaje enmascarado seguido de un ajuste fino multitarea son los que obtienen mejores resultados en nuestros experimentos".
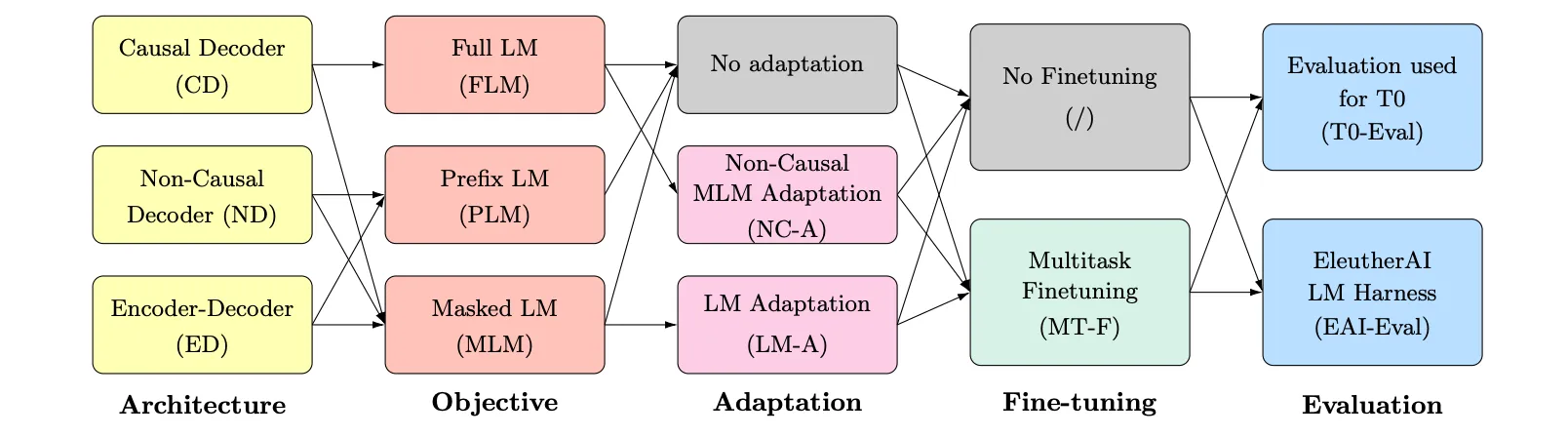
Bien, entonces codificador-decodificador > sólo decodificador > sólo codificador, ¿no?
Pues resulta que, aunque el citado artículo revelaba algunas ideas valiosas para desarrollar modelos más grandes. Hay que tener en cuenta otros factores a la hora de elegir la arquitectura.
Coste de formación
Para alcanzar el máximo potencial de ED, tendríamos que realizar un ajuste fino multitarea (que es básicamente un ajuste fino de instrucciones) sobre datos etiquetados y podría ser muy costoso, especialmente para los modelos más grandes.
Por otro lado, los modelos de DC consiguen un gran rendimiento gracias a su fuerte generalización de cero disparos, que funciona muy bien con la convención actual: aprendizaje autosupervisado sobre un corpus a gran escala.
Capacidad emergente
Los modelos comparados en el artículo tienen unos 5.000 parámetros y se han entrenado con 170.000 tokens. No es suficiente para explicar algo milagroso: la capacidad emergente de los LLM.
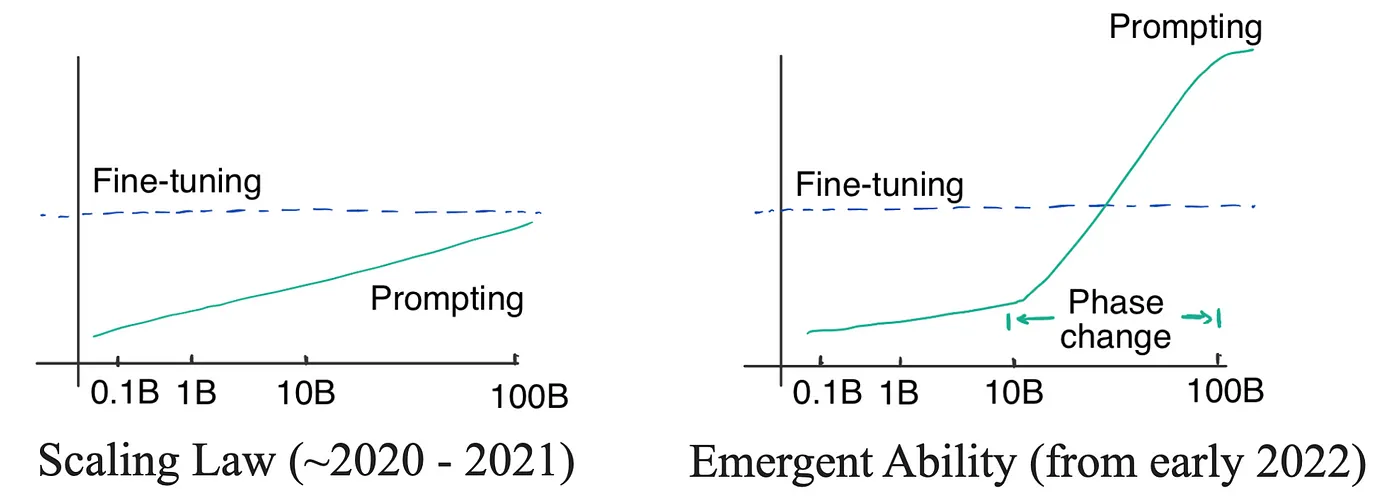
Las capacidades emergentes en los grandes modelos lingüísticos (LLM) se refieren al fenómeno en el que los modelos muestran capacidades nuevas y sofisticadas no enseñadas explícitamente durante el entrenamiento, que surgen de forma natural a medida que el modelo aumenta en tamaño y complejidad. Yao Fu ha escrito un magnífico blog sobre las capacidades emergentes en el que encontrará más información al respecto.
Básicamente, las capacidades emergentes permiten a LLM realizar cierto grado de razonamiento complejo. Por ejemplo, extraer conocimiento estructurado de un texto no estructurado.
Esta habilidad permite a LLM entender algunas tareas de PLN que subyacen naturalmente en el corpus de texto en el que fue entrenado. Para tareas más simples, podemos pensar en el LLM con habilidades emergentes que ya han sido afinadas durante el entrenamiento, y para tareas más complejas, puede descomponerlas en tareas más simples.
Las capacidades emergentes no benefician necesariamente a los modelos de sólo descodificador más que a los de ED, pero reducen la diferencia de rendimiento de los modelos de ED respecto a los de sólo descodificador con ajuste multitarea.
Aprendizaje en contexto a partir de estímulos
Otro aspecto a tener en cuenta son las instrucciones. Cuando usamos LLM, podemos aplicar métodos de ingeniería de avisos como proporcionar unos pocos ejemplos para ayudar a LLM a entender el contexto o la tarea.
En este artículo de Dai et al. los investigadores demostraron matemáticamente que dicha información en contexto puede tener un efecto similar al del descenso gradiente que actualiza el peso de la atención de la indicación de disparo cero.
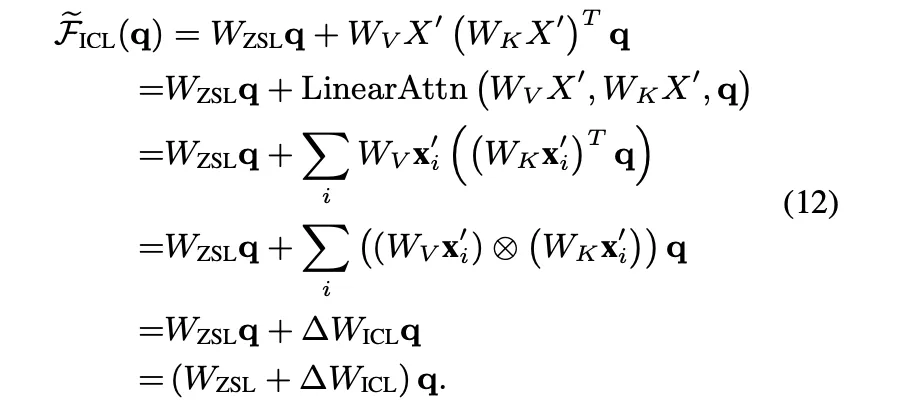
Si percibimos la incitación como la introducción de un gradiente en el peso de la atención, probablemente podamos esperar que tenga un efecto más directo para los modelos de sólo descodificador, ya que no necesita traducirse primero a un contexto intermedio antes de utilizarse para tareas generativas. Lógicamente, debería seguir funcionando para las arquitecturas codificador-decodificador, pero requiere que el codificador se ajuste cuidadosamente a un rendimiento óptimo, lo que podría resultar difícil.
Optimización de la eficiencia
En los modelos de sólo descodificación, las matrices de clave (K) y valor (V) de los tokens anteriores pueden reutilizarse para los tokens siguientes durante el proceso de descodificación.
Dado que cada posición sólo atiende a los tokens anteriores (debido al mecanismo de atención causal), las matrices K y V de estos tokens permanecen inalteradas. Este mecanismo de almacenamiento en caché mejora la eficiencia al evitar el recálculo de las matrices K y V para los tokens que ya han sido procesados, facilitando una generación más rápida y menores costes computacionales durante la inferencia en modelos autorregresivos como GPT.
Atención autorregresiva frente a bidireccional
Hay otro punto interesante que se plantea en relación con la diferencia en los mecanismos de atención subyacentes, es decir, autorregresivo para Decoder-only (Decodificador Causal) y Bidireccional para Encoder-Decoder.
A continuación podemos visualizar cómo atienden diferentes posiciones:
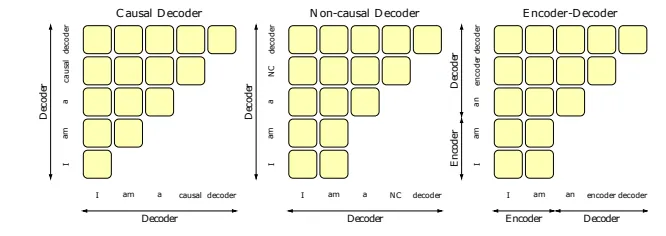
La forma en que se calcula la matriz de atención en la arquitectura transformadora es multiplicando dos matrices de dimensión inferior (Q y K^T) y aplicando después la operación softmax.
En las arquitecturas de sólo decodificador, la matriz de atención está restringida a una forma triangular inferior debido al enmascaramiento causal (para evitar que el modelo vea tokens futuros), que teóricamente mantiene su estado de rango completo: Cada elemento de la diagonal (que representa la autoatención) contribuye a que el determinante sea positivo (sólo se obtiene un resultado positivo de softmax).
El estatus de rango completo sugiere una capacidad expresiva teóricamente más fuerte.
Las otras dos arquitecturas generativas introducen la atención bidireccional y, por tanto, no garantizan el estado de rango completo de su matriz de atención. El autor sugiere que esto limitará el rendimiento del modelo. Puso en marcha un experimento para verificar esta suposición dividiendo la matriz de atención bidireccional en unidireccional, con la mitad de las cabezas de atención atendiendo hacia delante y la otra mitad hacia atrás.
A continuación, comparó el rendimiento de esta atención hacia delante y hacia atrás con el modelo de atención bidireccional completa. La atención FB funcionó mejor, lo que en cierto modo verificó esta teoría, pero la mejora fue bastante marginal y no pareció sugerir una diferencia significativa, especialmente cuando los modelos están suficientemente entrenados.
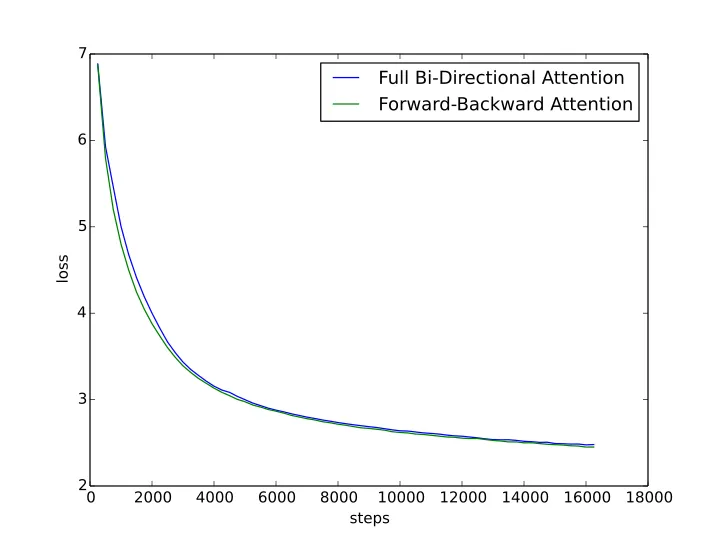
Intuitivamente tiene sentido. La atención bidireccional funciona como un arma de doble filo: acelera el proceso de aprendizaje, pero también "impide" que el modelo aprenda los patrones de predicción más profundos, esenciales para la generación. Es como aprender a escribir: rellenar espacios en blanco es más fácil que escribir un artículo entero palabra por palabra, pero sería una forma menos eficaz de practicar. Sin embargo, tras una enorme cantidad de entrenamiento, ambos enfoques consiguen el objetivo de aprender a escribir.
Qué he aprendido
La popularidad de la arquitectura de sólo decodificador se debe a su sencillez, su buena generalización de cero disparos y su menor coste de entrenamiento para alcanzar un rendimiento razonable.
Se han hecho muchos trabajos estudiando el rendimiento de las arquitecturas de sólo decodificador y de codificador-decodificador, pero dado que hay suficiente entrenamiento y tamaño de modelo, realmente no hay pruebas contundentes que demuestren que una arquitectura es superior a otra en términos de rendimiento final.
De hecho, Google Gemini demostró que el modelo codificador-decodificador puede funcionar igual de bien e incluso superar a las arquitecturas de sólo decodificador en algunas tareas.
El componente codificador es compatible con la "multimodalidad incorporada", ya que permite extraer información de entradas no textuales que podrían ser cruciales para la futura generación de LLM. Nuestra pregunta inicial debería ser por qué la mayoría de los LLM eran sólo decodificadores, ya que mostraban una era en la que todo el mundo había trabajado principalmente en el desarrollo de arquitecturas sólo decodificadoras.
No obstante, creo que revela una gran cantidad de información para comprender el mecanismo interno de funcionamiento de los LLM y la historia de su desarrollo. Es emocionante ver lo que vendrá después en la búsqueda de la inteligencia artificial.