
Retriever es la parte más importante del pipe RAG (Retrieval Augmented Generation)
Para comenzar con el proyecto, primero entenderemos algunos componentes críticos como el contexto de Servicio y Almacenamiento para construir tal aplicación.
Objetivos de aprendizaje
- Adquirir conocimientos sobre el pipeline RAG, entendiendo los roles de los componentes Retriever y Generator en la generación de respuestas contextuales.
- Aprender a integrar las técnicas de búsqueda de palabras clave y vectores para desarrollar un recuperador personalizado que mejore la precisión de la búsqueda en las aplicaciones RAG.
- Adquirir destreza en la utilización de LlamaIndex para la ingestión de datos, proporcionando contexto a los LLM y profundizando la conexión con los datos personalizados.
- Comprender la importancia de los recuperadores personalizados para mitigar las alucinaciones en las respuestas LLM mediante mecanismos de búsqueda híbridos.
- Explorar implementaciones avanzadas de recuperadores como reranking y HyDE para mejorar la relevancia de los documentos en RAG.
- Aprender a integrar Gemini LLM e incrustaciones dentro de LlamaIndex para la generación de respuestas y el almacenamiento de datos, mejorando las capacidades de RAG.
- Desarrollar habilidades de toma de decisiones para la configuración personalizada del recuperador, incluida la selección entre las operaciones AND y OR para la optimización de los resultados de búsqueda.
¿Qué es LlamaIndex?
El campo de los Grandes Modelos Lingüísticos se está expandiendo rápidamente, mejorando significativamente cada día. Con un número cada vez mayor de modelos que se publican a un ritmo acelerado, existe una necesidad creciente de integrar estos modelos con datos personalizados.
Esta integración proporciona a los negocios, empresas y usuarios finales más flexibilidad y una conexión más profunda con sus datos.
LlamaIndex, inicialmente conocido como GPT-index, es un marco de datos diseñado para sus aplicaciones LLM. A medida que aumenta la popularidad de la creación de chatbots personalizados basados en datos como ChatGPT, marcos como LlamaIndex adquieren cada vez más valor.
En su núcleo, LlamaIndex proporciona varios conectores de datos para facilitar la ingestión de datos. En este artículo, exploraremos cómo podemos pasar nuestros datos como contexto al LLM, este concepto es lo que entendemos por Retrieval Augmented Generation, RAG en abreviatura.
¿Qué es la RAG?
En Retrieval Augmented Generation, abreviado RAG, hay dos componentes principales: El Recuperador y el Generador.
- El Recuperador puede ser una base de datos vectorial, su trabajo consiste en recuperar los documentos relevantes para la consulta del usuario y pasarlos como contexto al indicador.
- El modelo generador es un modelo de lenguaje amplio, cuyo trabajo consiste en tomar los documentos recuperados junto con la consulta para generar una respuesta significativa a partir del contexto.
De esta forma, RAG es la solución óptima para el aprendizaje en contexto a través de un sistema automatizado.
Importancia de Retriever
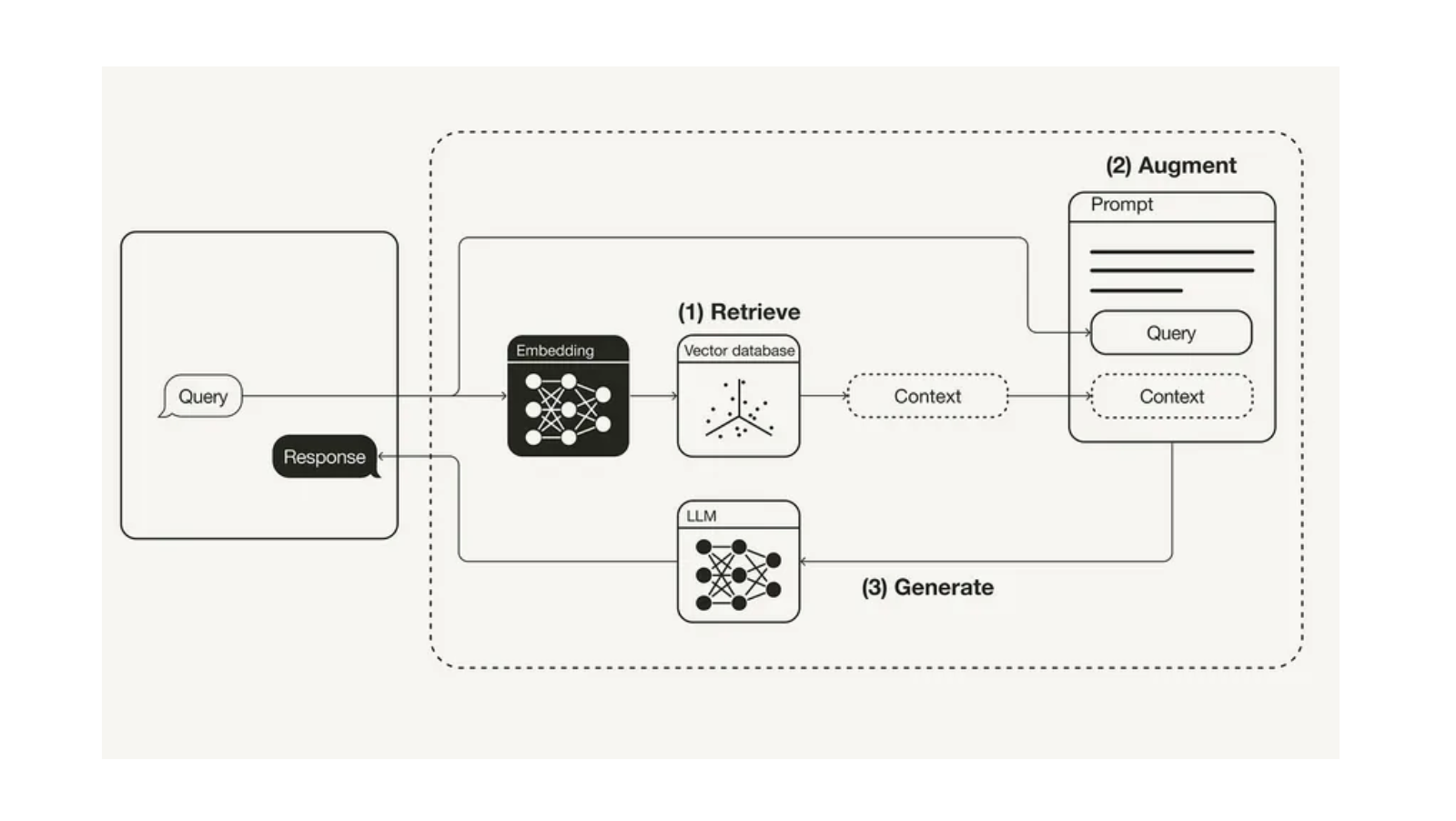
Comprendamos la importancia del componente Recuperador en la canalización RAG.
Para desarrollar un recuperador personalizado, es crucial determinar el tipo de recuperador que mejor se adapta a nuestras necesidades.
Para nuestros propósitos, implementaremos una Búsqueda Híbrida que integre tanto la Búsqueda por Palabra Clave como la Búsqueda Vectorial.
La búsqueda vectorial identifica los documentos relevantes para la consulta de un usuario basándose en la similitud o en la búsqueda semántica, mientras que la búsqueda por palabra clave encuentra los documentos basándose en la frecuencia de aparición del término.
Esta integración se puede conseguir de dos formas utilizando LlamaIndex.
Al construir el recuperador personalizado para la búsqueda híbrida, una decisión esencial es elegir entre utilizar una operación AND u OR:
- Operación AND: Este enfoque recupera los documentos que incluyen todos los términos especificados, por lo que es más restrictivo pero garantiza una alta relevancia. Se puede considerar como la intersección de resultados entre la Búsqueda por palabras clave y la Búsqueda vectorial.
- OperaciónOR: Este método recupera documentos que contienen cualquiera de los términos especificados, aumentando la amplitud de los resultados pero reduciendo potencialmente la relevancia. Se puede considerar como la unión de los resultados entre la búsqueda por palabra clave y la búsqueda vectorial.
Creación de un recuperador personalizado con LLamaIndex
Construyamos ahora un recuperador de clientes utilizando LlamaIndex.
Para construirlo necesitamos seguir ciertos pasos.
Paso 1: Instalación
Para comenzar con la implementación del código en Google Colab o Jupyter Notebook, es necesario instalar las librerías necesarias, principalmente en nuestro caso utilizaremos LlamaIndex para construir un recuperador personalizado, Gemini para el modelo de incrustación y la inferencia LLM, y PyPDF para el conector de datos.
!pip install llama-index
!pip install llama-index-multi-modal-llms-gemini
!pip install llama-index-embeddings-geminiPaso 2: Configurar la clave API de Google
En este proyecto, utilizaremos Google Gemini como modelo de lenguaje grande para generar respuestas y como modelo de incrustación para convertir y almacenar datos en vector-db o almacenamiento en memoria utilizando LlamaIndex.
Consigue tu clave API aquí
from getpass import getpassGOOGLE_API_KEY = getpass("Enter your Google API:")Paso 3: Cargar datos y crear nodo de documento
En LlamaIndex, la carga de datos se realiza mediante SimpleDirectoryLoader. En primer lugar, es necesario crear una carpeta y cargar los datos en cualquier formato en esta carpeta de datos. En nuestro ejemplo, voy a cargar un archivo PDF en la carpeta de datos.
Una vez cargado el documento, se analiza en nodos para dividir el documento en segmentos más pequeños. Un nodo es un esquema de datos definido en el marco de LlamaIndex.
La última versión de LlamaIndex ha actualizado su estructura de código, que ahora incluye definiciones para el analizador de nodos, el modelo de incrustación y LLM dentro de la Configuración.
from llama_index.core import SimpleDirectoryReader
from llama_index.core import Settingsdocuments = SimpleDirectoryReader('data').load_data()
nodes = Settings.node_parser.get_nodes_from_documents(documents)Paso 4: Configurar el modelo de incrustación y el modelo de lenguaje grande
Gemini soporta varios modelos, incluyendo gemini-pro, gemini-1.0-pro, gemini-1.5, modelo de visión, entre otros. En este caso, utilizaremos el modelo por defecto y proporcionaremos la clave API de Google.
Para el modelo de incrustación en Gemini, actualmente estamos utilizando embedding-001. Asegúrese de que se añade una clave de API válida.
from llama_index.embeddings.gemini import GeminiEmbedding
from llama_index.llms.gemini import GeminiSettings.embed_model = GeminiEmbedding(
model_name="models/embedding-001", api_key=GOOGLE_API_KEY
)
Settings.llm = Gemini(api_key=GOOGLE_API_KEY)Paso 5: Definir el contexto de almacenamiento y almacenar los datos
Una vez que los datos se analizan en nodos, LlamaIndex proporciona un contexto de almacenamiento, que ofrece almacenamiento de documentos por defecto para almacenar las incrustaciones vectoriales de los datos.
Este contexto de almacenamiento mantiene los datos en memoria, lo que permite indexarlos posteriormente.
from llama_index.core import StorageContextstorage_context = StorageContext.from_defaults()
storage_context.docstore.add_documents(nodes)Crear índice - Palabra clave e índice
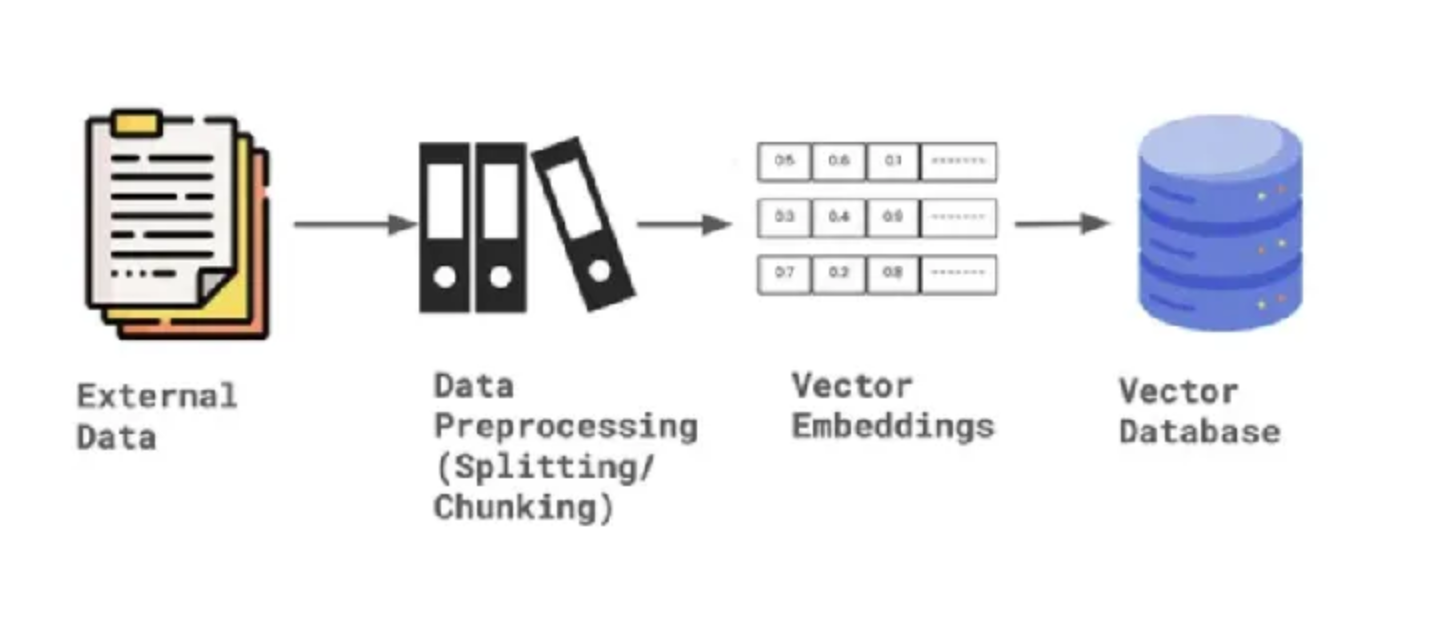
Para construir el recuperador personalizado para realizar la búsqueda híbrida necesitamos crear dos índices. En primer lugar, un índice vectorial que pueda realizar búsquedas vectoriales y, en segundo lugar, un índice de palabras clave que pueda realizar búsquedas de palabras clave.
Para crear el índice, necesitamos el contexto de almacenamiento y los documentos de nodo, junto con la configuración predeterminada del modelo de incrustación y el LLM.
from llama_index.core import SimpleKeywordTableIndex, VectorStoreIndex
vector_index = VectorStoreIndex(nodes, storage_context=storage_context)
keyword_index = SimpleKeywordTableIndex(nodes, storage_context=storage_context)Paso 6: Construir un recuperador personalizado
Para construir un recuperador personalizado para la búsqueda híbrida utilizando LlamaIndex, primero tenemos que definir el esquema, concretamente configurando adecuadamente los nodos.
Para el recuperador, se necesitan tanto un recuperador de índices vectoriales como un recuperador de palabras clave. Esto nos permite realizar búsquedas híbridas, integrando ambas técnicas para minimizar las alucinaciones. Además, debemos especificar el modo - AND u OR - dependiendo de cómo queramos combinar los resultados.
Una vez configurados los nodos, consultamos el paquete para cada ID de nodo utilizando tanto el recuperador de vectores como el de palabras clave. En función del modo seleccionado, definimos y finalizamos el recuperador personalizado.
from llama_index.core import QueryBundle
from llama_index.core.schema import NodeWithScorefrom llama_index.core.retrievers import (
BaseRetriever,
VectorIndexRetriever,
KeywordTableSimpleRetriever,
)
from typing import List
class CustomRetriever(BaseRetriever):
def __init__(
self,
vector_retriever: VectorIndexRetriever,
keyword_retriever: KeywordTableSimpleRetriever,
mode: str = "AND") -> None:
self._vector_retriever = vector_retriever
self._keyword_retriever = keyword_retriever
if mode not in ("AND", "OR"):
raise ValueError("Invalid mode.")
self._mode = mode
super().__init__()
def _retrieve(self, query_bundle: QueryBundle) -> List[NodeWithScore]:
vector_nodes = self._vector_retriever.retrieve(query_bundle)
keyword_nodes = self._keyword_retriever.retrieve(query_bundle)
vector_ids = {n.node.node_id for n in vector_nodes}
keyword_ids = {n.node.node_id for n in keyword_nodes}
combined_dict = {n.node.node_id: n for n in vector_nodes}
combined_dict.update({n.node.node_id: n for n in keyword_nodes})
if self._mode == "AND":
retrieve_ids = vector_ids.intersection(keyword_ids)
else:
retrieve_ids = vector_ids.union(keyword_ids)
retrieve_nodes = [combined_dict[r_id] for r_id in retrieve_ids]
return retrieve_nodes
Paso 7: Definir Recuperadores
Ahora que la clase retriever personalizada está definida, necesitamos instanciar el retriever y sintetizar el motor de consulta.
Un Sintetizador de Respuesta se utiliza para generar una respuesta desde un LLM basado en una consulta de usuario y un conjunto dado de trozos de texto. La salida de un Sintetizador de Respuesta es un objeto Respuesta, que toma el recuperador personalizado como uno de los parámetros.
from llama_index.core import get_response_synthesizer
from llama_index.core.query_engine import RetrieverQueryEnginevector_retriever = VectorIndexRetriever(index=vector_index, similarity_top_k=2)
keyword_retriever = KeywordTableSimpleRetriever(index=keyword_index)
# custom retriever => combine vector and keyword retriever
custom_retriever = CustomRetriever(vector_retriever, keyword_retriever)
# define response synthesizer
response_synthesizer = get_response_synthesizer()
custom_query_engine = RetrieverQueryEngine(
retriever=custom_retriever,
response_synthesizer=response_synthesizer,
)Paso 8: Ejecutar el motor de consulta del recuperador personalizado
Por último, hemos desarrollado nuestro recuperador personalizado que reduce significativamente las alucinaciones. Para probar su eficacia, ejecutamos consultas de usuario que incluían una consulta desde dentro del contexto y otra desde fuera del contexto, y luego evaluamos las respuestas generadas.
query = "what does the data context contain?"
print(custom_query_engine.query(query))
print(custom_query_engine.query("what is science?")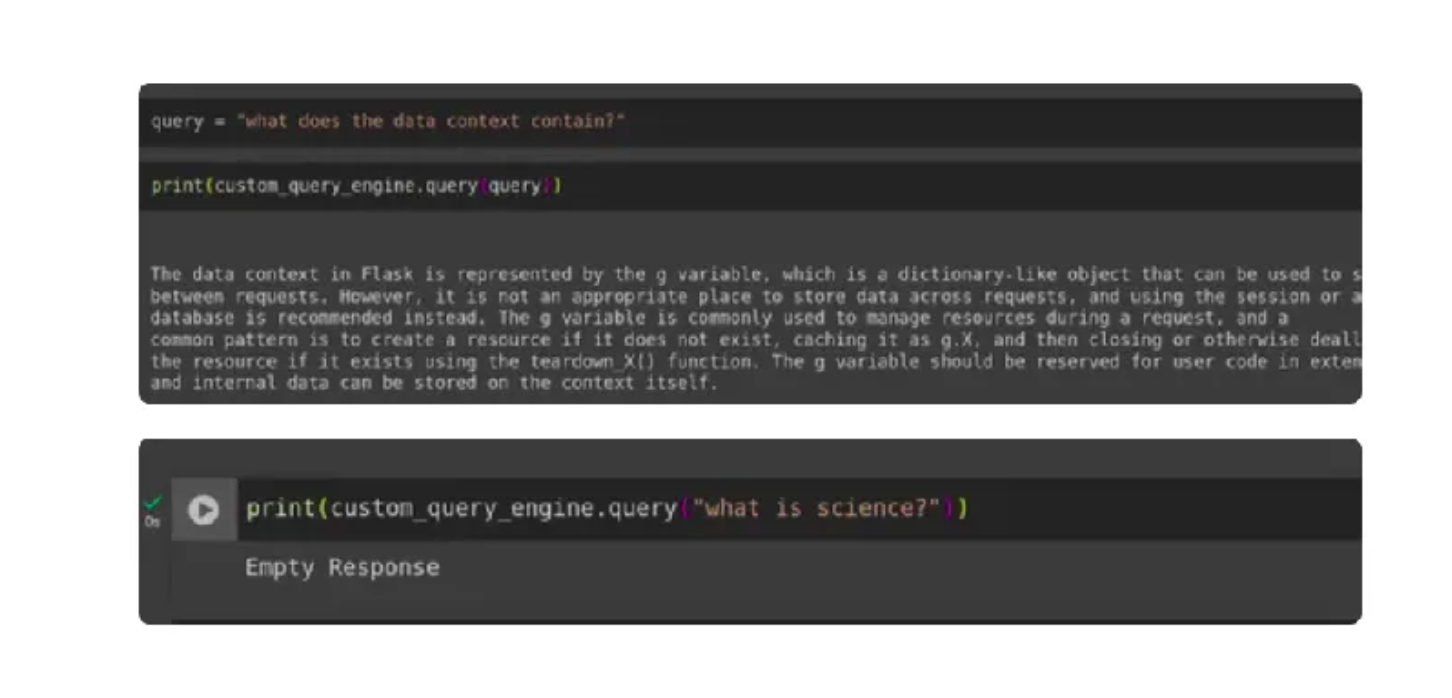
Conclusión
Hemos implementado con éxito un recuperador personalizado que realiza búsquedas híbridas combinando recuperadores de vectores y palabras clave mediante LlamaIndex, con el apoyo de Gemini LLM y Embeddings. Este enfoque reduce eficazmente hasta cierto punto las alucinaciones LLM en un pipeline RAG típico.
Puntos clave
- Desarrollo de un recuperador personalizado que integra recuperadores vectoriales y de palabras clave, mejorando las capacidades de búsqueda y la precisión en la identificación de documentos relevantes para RAG.
- Implementación de Gemini Embedding y LLM utilizando LlamaIndex Settings, que se sustituye en la última versión, anteriormente esto se hacía utilizando Service Context, que ahora está obsoleto.
- Al construir el recuperador personalizado, una decisión clave es si utilizar la operación AND o la OR, equilibrando la intersección y la unión de los resultados de la búsqueda por palabra clave y por vector según las necesidades específicas.
- La configuración del recuperador personalizado ayuda a reducir significativamente las alucinaciones en las respuestas de los modelos de lenguaje de gran tamaño mediante el uso de un mecanismo de búsqueda híbrido dentro de la canalización RAG.